本周小结:
第一周的工作主要对《Sensing, Computing, and Communications for Energy Harvesting IoTs: A Survey》进行了学习。作者概括了三个方向,分别是感知,计算和通信。
而我重点需要关注的三个方向是间歇计算,主动式无线电中的EH-optimized Transmission和反射式无线电。
本周我通过阅读两篇文献,学习了间歇计算是如何建模的。
1. 概括
Why:EH-IoTs 的能量供应是不确定的,易失性存储器显然在掉电后会丢失数据,因此必须周期性地将易失性状态保存在非易失性存储器中,这一技术称为checkpointing。当电能恢复时,程序可以从最近保存的状态中重新开始。但是 checkpointing 效率低下,不能直接用于间歇计算。
Challenge:能量开销;死循环;状态不一致;时序不一致。
Solving Direction:
- 检查点的预置与激活;
- 能量不足时checkpointing,之后立刻休眠。
- 基于任务流的编程方式。
- 看门狗checkpointing,引入定时器中断。
- 断电重启后确定设备当前时间,保证当前时间与世界时间一致非常重要。现有的方法包括:SRAM和电容的剩磁衰减来估计时间。
2. 文献一总结
2013 IEEE International Conference on Pervasive Computing and Communications (PerCom)《Idetic: A High-level Synthesis Approach for Enabling Long Computations on Transiently-powered ASICs》
2.1 设计时定位
背景:
作者对C/C++中的函数进行高级描述,并使用HLS期间生成的CFG分析数据路径。在此基础上,在寄存器传输级(RTL)引入了检查点。下图第一行是程序的CDFL输出文件,第二行是有限状态机信息,第三行是状态顺序,是通过展开有限状态机并将其转变为非循环的状态序列得到的。
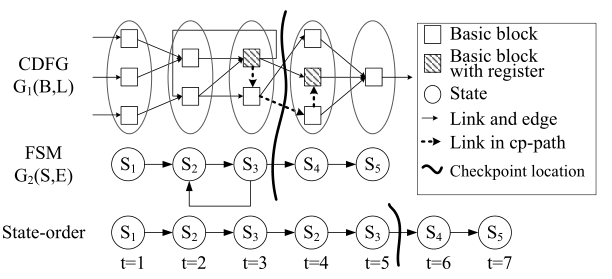
其中,$B=\{b _{1}, \ldots, b _{N}\}$ 是 basic-block 的集合(加法器,乘法器,条件器),$L$ 是链路(通过basic block的数据流)的集合。CDFG图用 $G _{1}(B, L)$ 表示。同样的,对于FSM图,用 $G _{2}(S, E)$ 表示。
我们用开销成本 $\operatorname{Cost}\left(e _{s _{i} s _{j}}\right)$ 表示在给定先前状态为 $s _i$ 的情况下在状态 $s _j$ 设置检查点所需的位数。作者给出了计算开销成本的伪代码:

Find optimal checkpoint:
优化目标:
在状态顺序中,完成所有 T 个状态的总能量 $C _{OF}(T,K)$ 最小,总能量包括计算和检查点的能量。
\[C _{OF}(T,K)=C _{CO}(T)+\sum _{t=t_1}^{t_K} C _{CP}(t)\]$t _1$,$t _K$指的是第一个检查点和最后一个检查点。$C _{CP}(t)$ 指的是在 $t$ 状态设置检查点的消耗。$C _{CO}(T)$ 指的是完成状态顺序中所有 T 个状态所消耗的计算成本。
约束:
检查点之间的距离不能太远,以防死循环,所以作者设置了下述限制:
两个连续的检查点的距离受到限制,最大距离不能超过 $D _ {max}$。
求解:
我们利用动态规划来寻找检查点位置。该算法如伪码-2所示。初始条件设置为确保第一个检查点位于距起点(第1-5行) $D _{max}$ 的最大距离。用$K _{max}$表示满足以下条件的检查点数目的一个上界:$K _{max}>\frac{T}{D _{max}}$。在 $t$ 处插入第 $k$ 个检查点的最小成本包括在该点设置检查点的成本(第8行)加上第 $t$ 个状态之前消耗的最小总能量(第9行)。

2.2 自适应在线学习
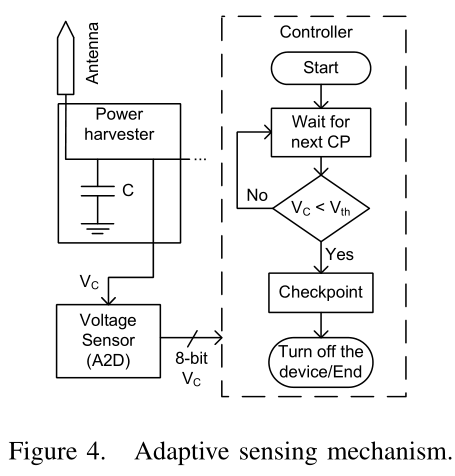
然而,上述设计时定位的检查点策略在输入能量足够的情况下可能效率不高。为了应对电源能量的变化,作者提出了一种自适应在线机制,通过A/D转换器读取电容器的电压,在每个检查点之前感知可用存储能量。如果电容器的能量水平(对应于 $V _c$ )大于两个连续检查点之间的最大能耗,则跳过检查点;两个连续检查点之间的最大能耗(对应于 $V _{th}$ )是通过功率模拟离线测量的。否则,完成预定的检查点并关闭设备以降低重新计算成本,如下图所示。假设平均输入功率远低于平均应用程序功耗。这一假设对于几种能量容量和充电率有限的能源回收源是现实的。
2.3 感悟
作者的模型太简单了,仅仅有计算开销和检查点开销;而且,设置的约束也太过于宽泛,当然作者的意图也很明显,通过一个简单的模型侧重于考虑在不同位置设置检查点对开销的影响。
3 文献二总结
2018 IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS《PATH: Performance-Aware Task Scheduling for Energy-Harvesting Nonvolatile Processors》
与文献一不同,这篇文献不设置检查点,程序的执行遵循任务流,任务通过控制流图连接,可以消除数据不一致的问题。
背景:
- EH-IoTs 的电源供应是不稳定的,人们设计了许多非易失性处理器(Nonvolatile processors,NVPs),这些NVPs可以对在断电之前在其上执行的任务进行快照,使得它们可以在电源恢复之后以可以忽略的开销继续工作。
- NVPs不是万能的,当考虑:处理器与外设之间的 I/O 操作,传感器上的传感操作的任务时,roll-back导致的损失依旧很大。因为:电源中断时涉及外设的任务(例如,感测、存储器访问和传输操作)不能被备份。(将roll-back导致的能量损失定义为电源切换开销)
- 即使许多研究者已经从硬件级别提出了一些外设的非易失性 I/O 结构,但是仍然需要任务调度方案来避免通用易失性外围设备不必要的回滚和初始化。
- 现有的研究方法中,根据单个任务在执行过程中是否可以被中断和调度,它们大致分为两类:任务间调度和任务内调度。
任务间调度将任务看作不可分割的单元,如果中断后需要重新执行,相关研究的学者致力于寻找任务级的自适应方案。
任务内调度任务可以再细分,通过中断执行中的任务来进一步提高性能,并根据功率插入其他任务来执行。
因此作者的研究目的是:研究任务内调度方案,以避免易失性外围设备不必要的回滚和初始化。
3.1 建模为MILP问题
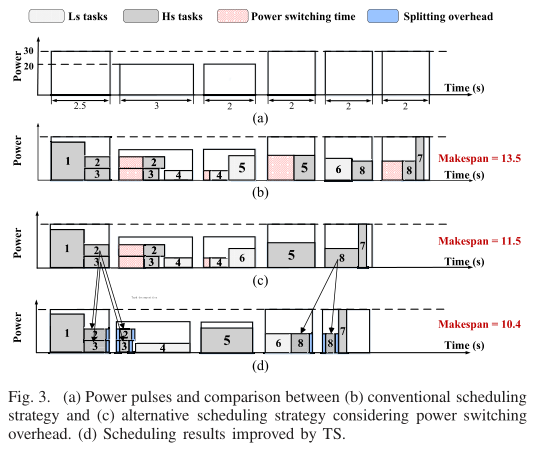
通过这张图可以很好地说明作者的模型思想。
外框就是供能的功率脉冲。内部填充的都是一个个任务,任务分为HS任务和LS任务,灰色的块对应HS任务,与外设相关,因roll-back而产生很大的电源切换开销(红色的块),白色的块是LS任务,可以在功率脉冲结束时中断在下一个脉冲时继续执行而仅产生微小的时间开销。图中的横坐标对应时间,纵坐标对应功率,作者的目标就是通过合理的调度,将HS和LS任务填充到供能的功率脉冲块中,在满足约束的条件下最小化总执行时间(横坐标值)。
目标:找到最短完成时间,实际上就是最小化功率脉冲个数。
峰值功率约束:任务功率必须低于功率脉冲的功率。
能量约束:并行执行的任务的总能量不能超过功率脉冲的能量。($E=P \times T$)
时间约束:对于两个有依赖关系的任务,只有前面的任务执行完成了,依赖其结果的任务才能执行。
电源切换约束:对于HS任务,不能中断执行否则会产生很大开销,这意味着HS任务只能被填充到一个功率脉冲中。
通过变换,作者将这一优化问题形式化为混合整数线性规划(MILP)问题,并通过LINGO求解,这是一个NP完全问题。
3.2 基于任务分割(TS)策略的离线启发式调度算法
作者在上述模型的基础上进一步优化模型,引入了任务内调度思想,将电源切换开销大,无法中断的HS任务分割成一个个的小HS任务,虽然每个小任务增加了额外的初始化开销,但是可以很大程度上避免roll-back导致大量的时间/能量消耗。
因为任务分割后任务数量太多,MILP求解效率低,作者提出了更高效的启发式算法:减少了每次进行MILP求解的变量数目,且优先保证HS任务执行。作者给出了求解的伪代码。
3.3 在线启发式调度算法
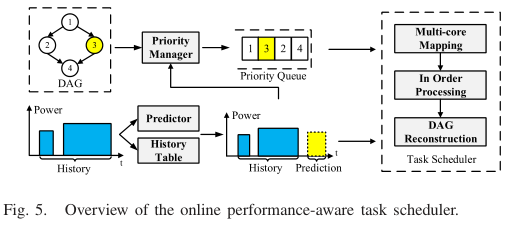
图5描述了在线调度器的原理。它由三个主要部分组成:能源预测器,优先级管理器和任务调度器。首先,维护一个历史记录表——包括最近 $N$ 个供能功率脉冲信息的记录表,以辅助预测和任务调度。优先级管理器首先根据功率预测结果和任务的DAG给出所有剩余任务的优先级顺序,并依次放入队列。然后,调度程序将任务映射到具有功率约束的传感器节点上,并按优先级顺序进行处理。
离线和在线的区别就是是否根据当前采集的能量水平动态决定最优调度结果。
3.4 感悟
这篇文章我认为作者建模得非常合理,而且之后的基于任务分割的离线启发式调度算法和在线启发式调度算法逐步将模型优化到更加合理,高效。放到建模比赛中,至少也是一篇国家级水平的建模论文😊。通过这两篇论文学到了很多,了解了间歇计算的两种求解模式——检查点和任务流分别是如何建模实现的。
4 讨论结果
-
目前的研究有点过于细致了,当前阶段应该主要横向看,看看各个领域的挑战和问题,是如何建模的。可以读一读比较早的高引用论文。
- 第一篇论文考虑了多个状态,全部状态结束后才完成计算,也就是多状态计算,而通信关注的计算可能更多的在单状态就完成计算。接下来的任务是看三个方向的论文,看看可以怎么融入多状态计算中,能不能受到启发。
- 单考虑间歇计算,非常局限,只涉及到单个点(机器)的本地运算,其实已经离通信越来越远了,所以应该引入多个点,考虑多个点之间是如何通信,并计算的,例如一个手机的计算任务同时交给多个基站,多个基站如何协调通信和计算的任务。甚至加入冗余编码,在若干台机器中只要能收到部分机器的运算结果也能完成任务。
- 第二条的三个方向是:MEC Energy efficiency MEC Youchang Sheng,Coded computation,Federated Learning