因为boyd的《凸优化》一书过于晦涩,所以只好暂时放弃看书学习的计划,转而通过看视频学习,最后再通过书本系统学习一遍。找了一圈视频,凌青老师的凸优化视频好评度最高,而且也是中科大的老师,因此果断向凌老师学习。所以便产生了以下的笔记。
凸优化:
\[\begin{array}{ll} \operatorname{minimize} & f_{0}(x) \\ \text { subject to } & f_{i}(x) \leqslant b_{i}, \quad i=1, \cdots, m \end{array}\]1 凸集
1.1 仿射集、凸集、凸锥集
直线:
\[x_1 \neq x_2 \in R^{n},\theta \in R,y=\theta x_1+(1-\theta)x_2=x_2+\theta (x_1-x_2)\]线段:
\[x_1 \neq x_2 \in R^{n},\theta \in [0,1],y=\theta x_1+(1-\theta)x_2=x_2+\theta (x_1-x_2)\]仿射集(Affine sets):一个集合 $C$ 是仿射集,若 $\forall x_1,x_2 \in C$,则连接 $x_1$ 与 $x_2$ 的直线也在集合内。
更泛化的定义: 设
\[x_1 \dots x_k \in C,\theta_1,\cdots ,\theta_k \in R, \theta_1+\dots+\theta_k=1\]仿射组合
\[\theta_1 x_1+\cdots+\theta_k x_k \in C\]所以直线是放射集,但是线段不是。
由第一个定义可以推出第二个定义,
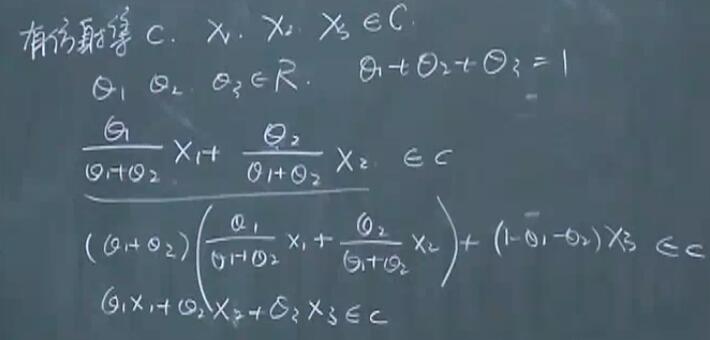 任意一个点也是仿射集。
任意一个点也是仿射集。
与 $C$(仿射集) 相关的子空间 $V$:
\[V=C-x_0=\{ x-x_0 \|x \in C \},\forall x_0 \in C\]可以证明 $V$ 是仿射集,且
\[\forall \alpha,\beta \in R => \alpha V_1 + \beta V_2 \in V\]证明:
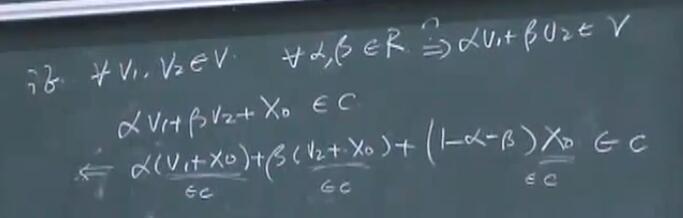
可以看出,子空间中,对$\alpha,\beta$ 没有要求,性质更好,且必经过原点。正是因为经过原点,所以叫做「子空间」。
线性方程组的解集是仿射集。
证明:
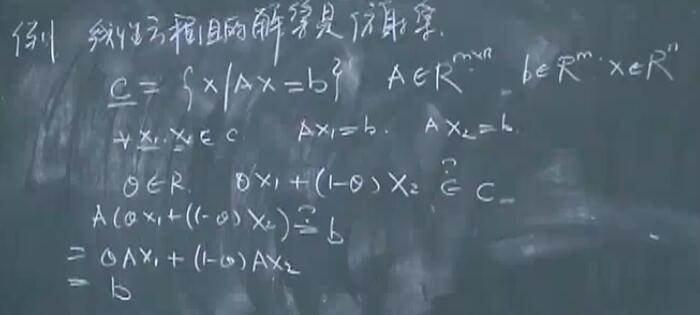
上面的仿射集的子空间:
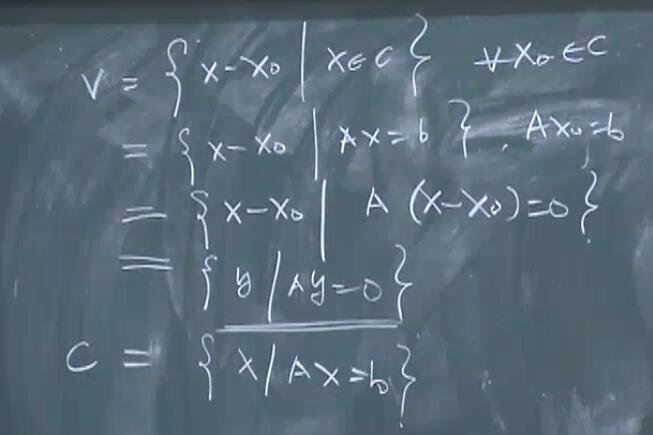 由此可以得出,任意一个仿射集,只要作了平移,使得任意一个点落在原点处,这样一个集合就是子空间,且把 $Ax=b$ 中的 $b$ 替换成了 0,叫做「化零空间」。
由此可以得出,任意一个仿射集,只要作了平移,使得任意一个点落在原点处,这样一个集合就是子空间,且把 $Ax=b$ 中的 $b$ 替换成了 0,叫做「化零空间」。
实际上,上述定理反过来也成立。
「仿射包」:包含C的最小的仿射集。
\[aff C = \{ \theta x_1+\cdots+\theta_k x_k| \forall x_1,\cdots,x_k \in C,\forall \theta_1+\cdots+\theta_k=1 \}\]凸集 Convex Set:一个集合 C 是凸集,当任意两点之间的线段仍然在 C 内。
凸集的泛化定义:C为凸集$<=>$任意元素的凸组合在C内
仿射集一定是一个凸集。
空集也是仿射集,因此也是凸集和凸锥。
$x_1, \cdots ,x_k$ 的凸组合:
\[\theta_1 x_1 + \cdots +\theta_k x_k\]其中
\[\theta_1,\cdots,\theta_k \in R,\theta_1+\cdots+\theta_k=1,\theta_1,\cdots,\theta_k \in [0,1]\]「凸包」:
\[Conv C=\{ \theta_1 x_1+\cdots+\theta_k x_k|\forall x_1,\cdots,x_k \in C,\forall \theta_1,\cdots,\theta_k \in [0,1],\theta_1+\cdots+\theta_k=1 \},C \in R^{n}\]离散点的凸包是最外围的点围成的范围集。
「锥」Cone:
C是锥等价于
\[\forall x \in C,\theta \geq 0, 有 \theta x \in C\]C是凸锥等价于
\[\forall x_1,x_2 \in C,\theta_1,\theta_2 \geq 0$,有 x_1 \theta_1+x_2 \theta_2 \in C\]任意一个点不一定是一个凸锥,只有原点才是凸锥。
凸锥组合:
\[\theta_1 x_1+\cdots+\theta_k x_k,\theta_1,\cdots,\theta_k \geq 0\]凸锥包:
\[\{\theta_1 x_1+\cdots+\theta_k x_k | x_1,\cdots,x_k \in C, \theta_1,\cdots,\theta_k \geq 0\]
总结:
仿射集、凸集、凸锥;仿射组合、凸组合、凸锥组合;仿射包,凸包、凸锥包
K个点 $x_1,\cdots,x_k \in C$,选取 $\theta_1,\cdots,\theta_k \in R $ 构造「组合」 $\theta_1 x_1+\cdots+\theta_k x_k$:
对于仿射集,$\theta_1+\cdots+\theta_k=1$,仿射组合 $\in C$;对于凸集:$\theta_1+\cdots+\theta_k=1$,且$\theta_i \geq 0$,对于凸锥集:$\theta_i \geq 0$。
1.2 几种重要的凸集
$R^{n}$ 空间,是仿射集、凸集和凸锥集。
$R^{n}$ 空间的子空间(注意区别于C的子空间)仍然是仿射集,凸集和凸锥集。
任意直线一定是一个仿射集,不是凸集,过原点是凸锥。
任意线段一定是凸集,可能是仿射集(化为一个点),可能是凸锥(在原点的点)。
射线可能是仿射集(缩减为一个点),可能是凸锥(过原点的射线)。
超平面Hyperplane:
\[\{ x|a^{T}x=b \},x,a \in R^{n},b \in R ,a \neq 0\]半空间halfspace:
\[a^{T}x \geq b$ 或者 $a^{T}x \leq b\]超平面是仿射集、凸集,过原点就是凸锥。
半空间是凸集,不是仿射集,不一定是凸锥($b=0$时候是凸锥)
球:
\[B\left(x_{c}, r\right)=\left\{x \mid\left\|x-x_{c}\right\|_{2} \leqslant r\right\}=\left\{x \mid\left(x-x_{c}\right)^{T}\left(x-x_{c}\right) \leqslant r^{2}\right\}\]椭球:
\[\mathcal{E}=\left\{x \mid\left(x-x_{c}\right)^{T} P^{-1}\left(x-x_{c}\right) \leqslant 1\right\}\]其中 $P$ 是对称正定矩阵。$P=r^2I_n$ 时,椭球变为球。
多面体Polyhedron:
\[\mathcal{P}=\left\{x \mid a_{j}^{T} x \leqslant b_{j}, j=1, \cdots, m, c_{j}^{T} x=d_{j}, j=1, \cdots, p\right\}\]有界多面体:有界
多面体是凸集
单纯形Simplex
单纯形是一类重要的多面体。设 $k+1$ 个点 $v_{0}, \cdots, v_{k} \in \mathbf{R}^{n}$ 仿射独立, 即 $v_{1}-v_{0}, \cdots, v_{k}-v_{0}$ 线性独立, 那么, 这些点决定了一个单纯形, 如下
\[C=\operatorname{conv}\left\{v_{0}, \cdots, v_{k}\right\}=\left\{\theta_{0} v_{0}+\cdots+\theta_{k} v_{k} \mid \theta \succeq 0, \mathbf{1}^{T} \theta=1\right\}\]其中 1 表示所有分量均为一的向量。这个单纯形的仿射维数为 $k$, 因此也称为 $\mathbf{R}^{n}$ 空间的 $k$ 维单纯形。
即在线性无关点中构造凸包。
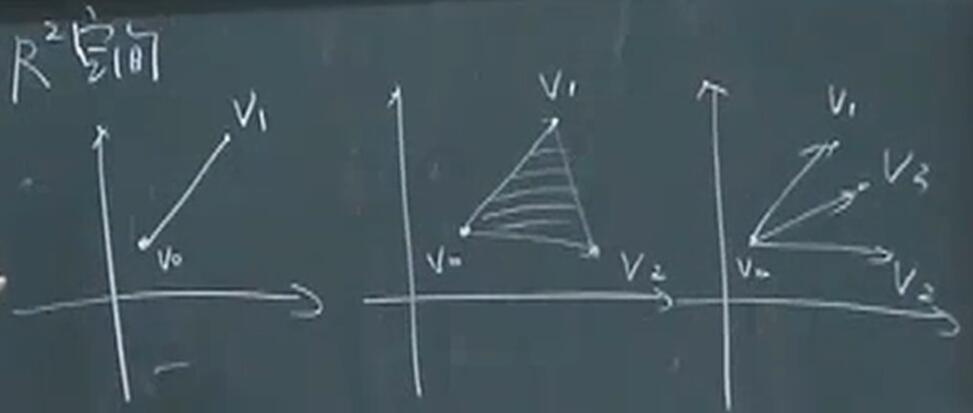 可以看出,在二维空间中不存在四边形,所以在n维空间中最多可以构造由n+1个点组成的凸包。超过n+1个点则$v_1-v_0,\cdots,v_k-v_0$ 不线性独立
可以看出,在二维空间中不存在四边形,所以在n维空间中最多可以构造由n+1个点组成的凸包。超过n+1个点则$v_1-v_0,\cdots,v_k-v_0$ 不线性独立
任意一个单纯性是一个多面体。
半正定锥
集合 $S_{+}^{n}$ 是一个凸锥: 如果 $\theta_{1}, \theta_{2} \geq 0$ 并且 $A, B \in S_{+}^{n}$, 那么 $\theta_{1} A+\theta_{2} B \in {S}_{+}^{n}$
1.3 保凸运算
交集具有保凸性:若 $S_1,\cdots,S_k$ 为凸,则 $S_1 \cap \cdots S_k$ 为凸集。
并集不一定具有保凸性质。
仿射函数:$f:R^{n} \rightarrow R^{m}$ 是仿射的,当$f(x)=Ax+b,A \in R^{m \times n},b \in R^{m}$
若 $S \subset R^{n}$ 为凸,$f:R^{n} \rightarrow R^{m}$ 仿射,则 $f(S)=\{ f(x)|x \in S \}$ 为凸。
逆仿射运算也具有保凸性。$g^{-1}(S)=\{ x \mid f(x) \in S \}$
两个凸集的和是凸的:
\[S_1+S_2=\{ x+y \mid x \in S_1,y \in S_2 \}\]两个凸集的乘积是凸的:
\[S_1 \times S_2=\{ (x+y) \mid x \in S_1,y \in S_2 \}\]下面举两个仿射函数的例子:
 其中半正定锥是 $S^{n}_+$
其中半正定锥是 $S^{n}_+$
透视函数:
\[P:R^{n+1} \rightarrow R^{n},\operatorname{dom} P=R^{n} \times R_{++},P(z,t)=\frac{z}{t},z \in R^{n},t \in R_{++}\]其中,$R^{n} \times R_{++}$ 表示矩阵 $P$ 的前n维是实矩阵,最后一维是实矩阵。
任意一个凸集经过透视函数后仍为凸集。透视函数的含义可以解释为小孔成像的过程,小孔在原点,物体通过小孔成像得到的成像点的最后一维坐标是-1。
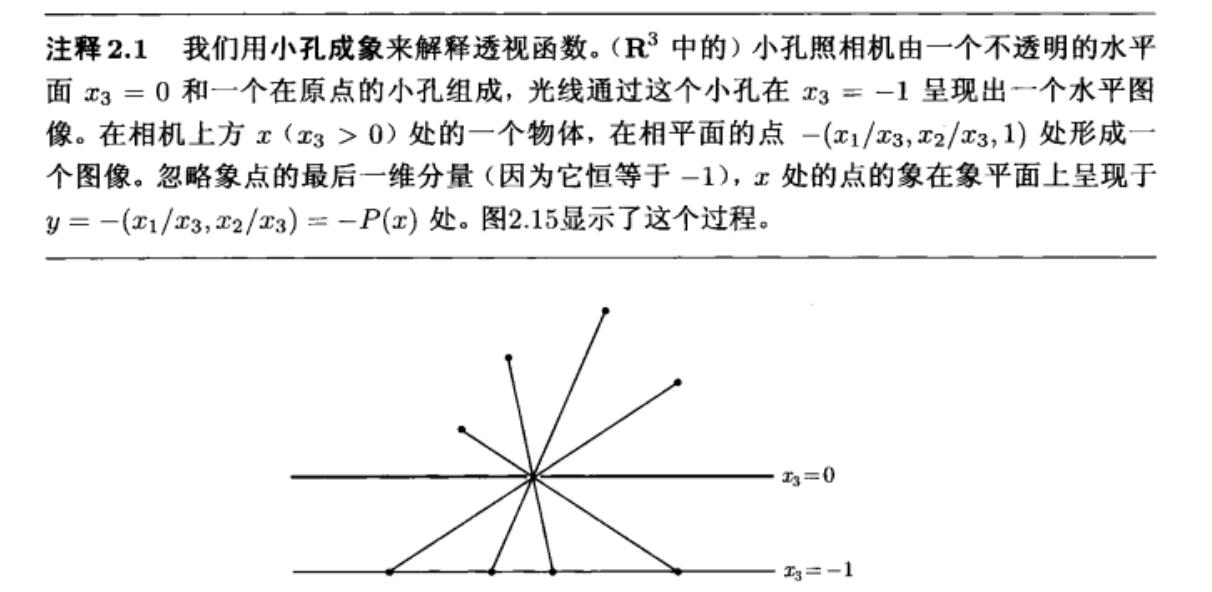
任意凸集的反透视映射 $P^{-1}(C)$ 仍是凸集。
\[P^{-1}(C)=\{(x,t) \in R^{n+1},\mid \frac{x}{t} \in C,t > 0 \}\]线性分式(数)函数:

2 凸函数
2.1 凸函数的定义:
凸函数第S一定义:函数 $ f:R^{n} \rightarrow R $ 是凸的,如果 $\operatorname{dom} f$ 是凸集,且对于任意 $x,y \in \operatorname{dom} f$ 和任意 $0 \leq \theta \leq 1$,有:
\[f(\theta x + (1-\theta)y) \leq \theta f(x)+(1-\theta)f(y)\]概括一下就是凸组合的函数值小于等于函数的凸组合。
凸函数的扩展
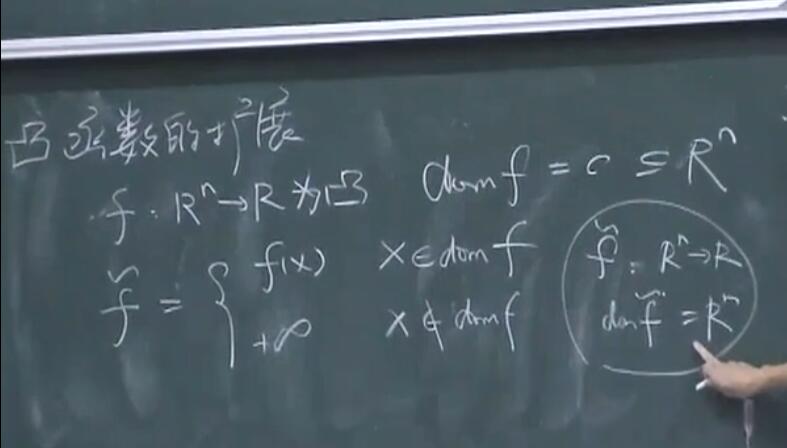 扩展后的凸函数依旧是一个凸集。可以证明,如果 $x \notin \operatorname{dom} f$ 时,$f$ 不扩展到正无穷,而是扩展到有限数,则 $f$ 不是凸集。
扩展后的凸函数依旧是一个凸集。可以证明,如果 $x \notin \operatorname{dom} f$ 时,$f$ 不扩展到正无穷,而是扩展到有限数,则 $f$ 不是凸集。
凸函数的第二定义
函数是凸的, 当且仅当其在与其定义域相交的任何直线上都是凸的。换言之, 函数 $f$ 是凸的, 当且仅当对于任意 $x \in \operatorname{dom} f$ 和任意向量 $v$, 函数 $g(t)=f(x+t v)$ 是凸的(其定义域为 ${t \mid x+t v \in \operatorname{dom} f}$)。这个性质非常有用, 因为它容许我们通过将函数限制在直线上来判断其是否是凸函数。
第二定义把高维($x$,$n$ 维)复杂问题降到低维($t$,1维)上。
一阶条件(凸函数的第三定义)
设 $f:R^{n} \rightarrow R$ 可微,即梯度 $\nabla f$ 在 $\operatorname{dom} f$ 上均存在,则 $f$ 为凸函数等价于:
- $\operatorname{dom} f$ 为凸。
- $f$ 满足:
二阶条件(凸函数的第四定义)
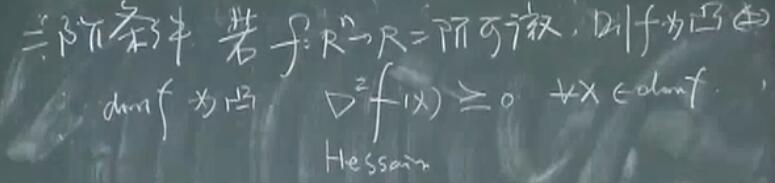 $\nabla^{2}f(x) \succ 0 \rightarrow$ $f$ 严格凸
$\nabla^{2}f(x) \succ 0 \rightarrow$ $f$ 严格凸
反之不一定成立:比如 $f=x^{4}$ 是严格凸的(一维情况),但是其Hessian可能等于0(此时上述条件简化为f二阶导大于0)。
例子:
- 不满足定义域是凸集的条件,因此 $f$ 不是凸的。
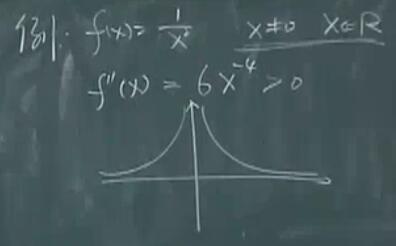
- 仿射函数 $f(x)=Ax+b$,证明可以用二阶条件证。
- 指数函数 $f(x)=e^{ax},x \in R$,证明可以用二阶条件证。
- 幂函数 $f(x)=x^{a},x \in R_{++}$ 可以是凹的,也可能是凸的。
- 绝对值的幂函数: $f(x)=\lvert x \lvert ^{p},x \in R$ 在 $p \geq 1$ 条件下一定是一个凸函数。
- 对数函数:$f(x)=log(x),x \in R_{++}$ 凹函数
- 负熵:$f(x)=x log(x),x \in R_{++}$ 严格凸函数
- 范数:$R^{n} 上的任意范数均为凸函数。
- 零范数(非零元素数目):非凸。(零范数不满足范数的性质1,因此不是范数)
- 极大值函数:$f(x)=max(x_1,\cdots,x_n),x \in R^{n}$ 为凸函数。可以直接用凸优化的定义1去证明其凸性。或者用解析逼近:
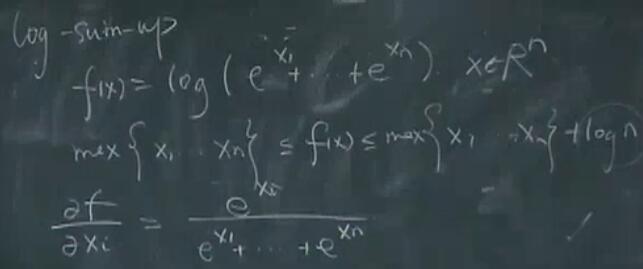
 注意:应该是一范数,而不是二范数。
注意:应该是一范数,而不是二范数。

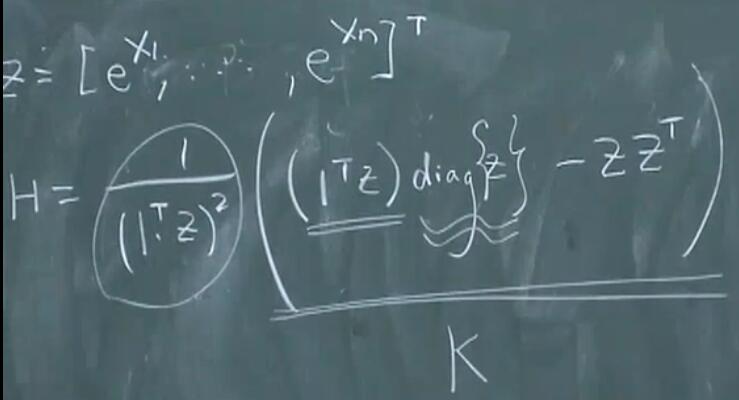
 利用柯西施瓦兹不等式即可证明大于等于0。
利用柯西施瓦兹不等式即可证明大于等于0。
2.2 保凸运算:
非负加权求和仍然是凸函数: $f=w_{1} f_{1}+\cdots+w_{m} f_{m},w_{i} \geq 0$,$f_{i}$ 为凸。
非负加权和的积分形式: 非负加权求和的性质可以扩展至无限项的求和以及积分的情形。例如, 如果固定任意 $y \in A$, 函数 $f(x, y)$ 关于 $x$ 是凸函数, 且对任意 $y \in A$, 有 $w(y) \geqslant 0$, 则函数 $g(x)=\int_{\mathcal{A}} w(y) f(x, y) d y$ 关于 $x$ 是凸函数 (若此积分存在)。
复合仿射映射:假设函数 $f: R^{n} \rightarrow R, A \in R^{n \times m}$,以及 $b \in {R}^{n}$,定义 $g: R^{m} \rightarrow R$ 为
\[g(x)=f(A x+b),\]其中 $\operatorname{dom} g=\{x \mid A x+b \in \operatorname{dom} f\}$。若函数 $f$ 是凸函数, 则函数 $g$ 是凸函数; 如果函 数 $f$ 是凹函数, 那么函数 $g$ 是凹函数。
逐点最大函数(几个凸函数的极大值函数)或者叫做分段线性函数:
\[f(x)=max(f_1(x),f_2(x)),\operatorname{dom} f=\operatorname{dom} f_1 \cap \operatorname{dom} f_2\]为凸函数。
向量中 $r$ 个最大元素的和也是凸函数
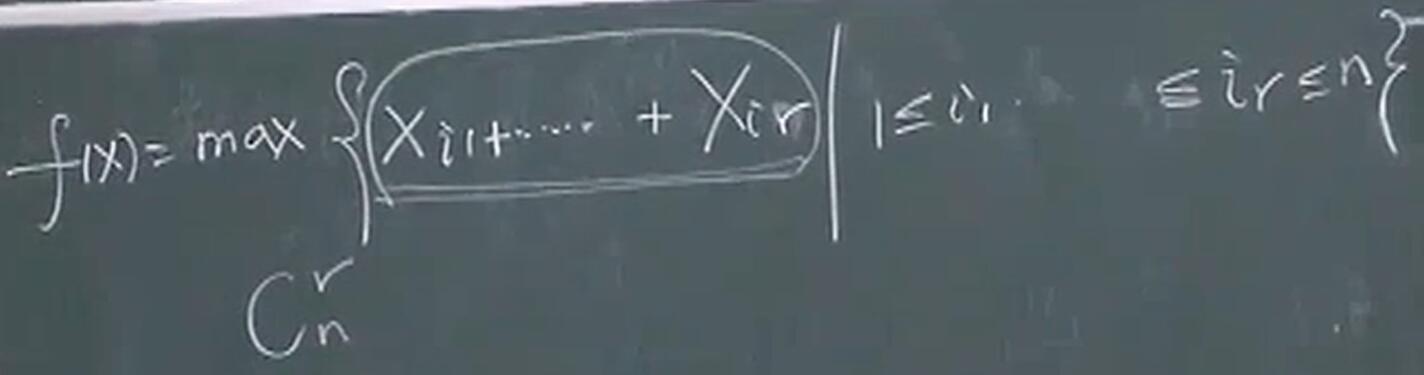 无穷多个函数的上确界也是凸的
无穷多个函数的上确界也是凸的
逐点最大的性质可以扩展至无限个凸函数的逐点上确界。如果对于任意 $y \in \mathcal{A}$, 函 数 $f(x, y)$ 关于 $x$ 都是凸的, 则函数 $g$
\[g(x)=\sup _{y \in \mathcal{A}} f(x, y)\]关于 $x$ 亦是凸的。此时, 函数 $g$ 的定义域为
\[\operatorname{dom} g=\{x \mid(x, y) \in \operatorname{dom} f \ \ \forall y \in \mathcal{A}, \sup _{y \in \mathcal{A}} f(x, y)<\infty \}\]若 $f(x,u)$ 为凸,则 $g(u)=\inf _x f(x,u)$ 为凸函数。
证明: 设 $(x_1,u_1),(x_2,u_2) \in \operatorname{dom} f$,根据凸函数的定义
\[\begin{aligned} \forall \theta \in [0,1] \ \theta f(x_1,u_1)+(1-\theta) f(x_2,u_2)\\ \geq f(\theta x_1 + (1-\theta) x_2,\theta u_1 + (1-\theta) u_2) \end{aligned}\]对不等式两边取极小,不等式仍成立,根据 $g(u)=\inf _x f(x,u)$,原式变为
\[\theta g(u_1)+(1-\theta) g(u_2) \geq g(\theta u_1+(1-\theta)u_2)\]$g(u)$ 是凸函数,得证。
复合运算(标量复合): 给定函数 $h:R^{k} \rightarrow R,g:R^{n} \rightarrow R^{k}$,定义复合函数:$f=h \circ g:R^{n} \rightarrow R$ 为
\[f(x)=h(g(x)),\operatorname{dom} f=\{x \in \operatorname{dom} g \mid g(x) \in \operatorname{dom} h \}\]$f$ 为凸函数需要满足以下条件:
- 如果 $h$ 是凸函数且非减, $g$ 是凸函数, 则 $f$ 是凸函数,
- 如果 $h$ 是凸函数且非增, $g$ 是凹函数, 则 $f$ 是凸函数,
- 如果 $h$ 是凹函数且非减, $g$ 是凹函数, 则 $f$ 是凹函数,
- 如果 $h$ 是凹函数且非增, $g$ 是凸函数, 则 $f$ 是凹函数。
上述结论需要保证 $g$ 和 $h$ 二次可微且定义域为R。
对于更一般的情况,不再假设 $h$ 和 $g$ 可微或者 $\operatorname{dom} g=R^{n}$,$\operatorname{dom} h=R^{k}$,一些相似规则仍然成立:
透视函数:
给定函数 $f: R^{n} \rightarrow R$, 则 $f$ 的透视函数 $g: R^{n+1} \rightarrow R$ 定义为
其定义域为
\[\operatorname{\operatorname{dom}} g=\{(x, t) \mid x / t \in \operatorname{\operatorname{dom}} f, t>0\}\]透视运算是保凸运算: 如果函数 $f$ 是凸函数, 则其透视函数 $g$ 也是凸函数。类似地, 若 $f$ 是凹函数, 则 $g$ 亦是凹函数。
例子:负对数
\[f(x)=-\operatorname{log} x,x \in R_{++}\]是凸函数,则透视函数为
\[g(x, t)=-t \log (x / t)=t \log (t / x)=t \log t-t \log x\]在 $R_{++}^{2}$ 上是凸函数。函数 $g$ 称为关于 $t$ 和 $x$ 的相对熵。
将上面的 $x$ 和 $t$ 扩展到 $n$ 维:
\[g(u,v)=\sum_{i=1}^{n} u_{i} \log \left(u_{i} / v_{i}\right)\]因为它是一系列 $u_i,v_{i}$ 的相对熵的和,因此关于 $(u,v)$ 是凸函数。
还有一个与之密切相关的KL散度:
\[D_{kl}(u, v)=\sum_{i=1}^{n}\left(u_{i} \log \left(u_{i} / v_{i}\right)-u_{i}+v_{i}\right)\]它是 $(u,v)$ 的相对熵和仿射函数的非负加权和,因此是凸函数。
2.3 共轭函数:
共轭函数:
对于 $f:R^{n} \rightarrow R$,
\[f^{*}(y)=\sup _{x \in \operatorname{dom} f}\left(y^{T} x-f(x)\right)\]称为函数 $f$ 的共轭函数。使上述上确界有限,即差值 $y^{T} x-f(x)$ 在 $\operatorname{dom} f$ 有上界的所有 $y \in \mathbf{R}^{n}$ 构成了共轭函数的定义域。
基本性质:
- 设函数 $f$ 是凸函数且可微, 其定义域为 $\operatorname{dom} f={R}^{n}$, 使 $y^{T} x-f(x)$ 取最大的 $x^*$ 满足 $y=\nabla f(x^*)$,反之,若 $x^*$ 满足 $y=\nabla f\left(x^*\right), y^{T} x-f(x)$ 在 $x^*$ 处取最大值。
- 不管 $f(x)$ 是否凸,$f^{*}(y)$ 一定是凸函数。
例子:严格凸的二次函数。考虑函数 $f(x)=\frac{1}{2} x^{T} Q x, Q \in S_{++}^{n}$ 。对所有的 $y, x$ 的函数 $y^{T} x-\frac{1}{2} x^{T} Q x$ 都有上界并在 $x=Q^{-1} y$ 处达到上确界, 因此
\[f^{*}(y)=\frac{1}{2} y^{T} Q^{-1} y\]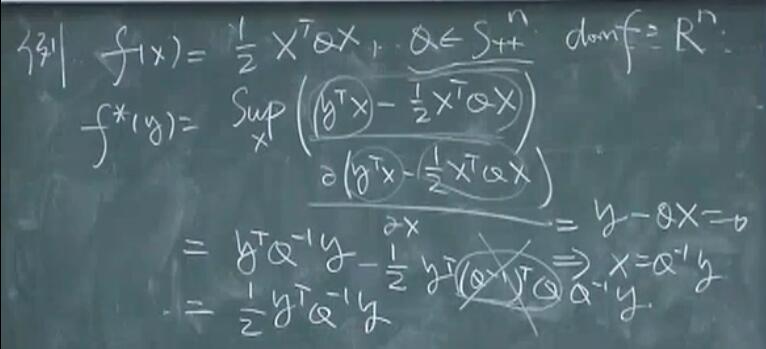 二次函数的共轭就是把 $x$ 换成 $y$ ,$Q$ 换成 $Q^{-1}$。
二次函数的共轭就是把 $x$ 换成 $y$ ,$Q$ 换成 $Q^{-1}$。
$(f^*)^*=f$ 不一定成立,只有当f是凸函数且为闭函数,上式才成立。
2.4 拟凸函数
定义:
函数 $f: \mathbf{R}^{n} \rightarrow \mathbf{R}$ 称为拟凸函数(或者单峰函数),如果其定义域及所有下水平集($\alpha-Sublevel \ Set$)
\[S_{\alpha}=\{x \in \operatorname{dom} f \mid f(x) \leqslant \alpha\},\]$\alpha \in \mathbf{R}$,都是凸集。凸函数的所有下水平集都是凸集,所以也是拟凸函数。但是拟凸函数不一定是凸函数。
上面定义说明了凸集和凸函数的关系。
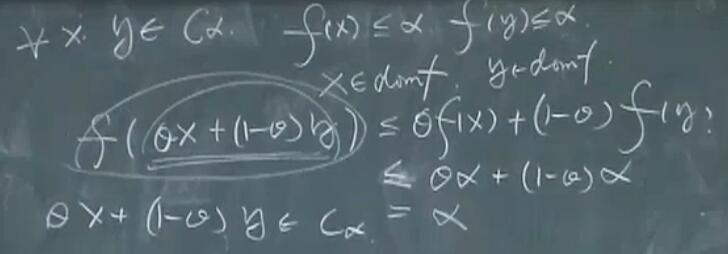 最后一步,由 $\alpha$ 的任意性可以得出所有下水平集都是凸集。
最后一步,由 $\alpha$ 的任意性可以得出所有下水平集都是凸集。
拟凹函数:如果 $-f$ 是拟凸函数, 即每个上水平集 $\{x \mid f(x) \geqslant \alpha\}$ 是凸集,则函数 $f$ 是拟凹函数。 拟线性函数:若某函数既是拟凸函数又是拟凹函数, 其为拟线性函数。数学上,如果其定义域和所有的水平集 $\{x \mid f(x)=\alpha\}$ 都是凸集,函数就是拟线性函数。
拟凸函数的Jensen不等式:
函数 $f$ 是拟凸函数的充要条件是, $\operatorname{dom} f$ 是 凸集, 且对于任意 $x, y \in$ $\operatorname{dom} f$ 及 $0 \leqslant \theta \leqslant 1$, 有
可微拟凸函数一阶条件:
设函数 $f: \mathbf{R}^{n} \rightarrow \mathbf{R}$ 可微, 则函数 $f$ 是拟凸的充要条件是, $\operatorname{dom} f$ 是凸集, 且对于任意 $x, y \in \operatorname{dom} f$ 有
\[f(y) \leqslant f(x) \Longrightarrow \nabla f(x)^{T}(y-x) \leqslant 0\]上式表示,如果满足 $f(y) \leqslant f(x)$,可以推出 $\nabla f(x)^{T}(y-x) \leqslant 0$ 的话,则 $f$ 是拟凸函数(挺奇怪的定义)。
凸函数的一阶条件告诉我们,如果 $\nabla f(x)^T(x)=0$,则对于任何 $y$,必有 $f(y) \geq f(x)$,即 $f(x)$ 是全局最优点。
但是拟凸函数的一阶条件:若$\nabla f(x)^T(x)=0$,则对于任何 $y$,$f(y) \leq f(x) \Longrightarrow 0 \leq 0$,并不能得出 $f(x)$ 是全局最优点的结论。
可微拟凸函数二阶条件:
假设函数 $f$ 二次可微。如果函数 $f$ 是拟凸函数,则对于任意 $x \in \operatorname{dom} f$ 以及任意 $y \in \mathbf{R}^{n}$ 有
\[y^{T} \nabla f(x)=0 \Rightarrow y^{T} \nabla^{2} f(x) y \geqslant 0\]对于定义在 $\mathbf{R}$ 上的拟凸函数, 上述条件可以简化为如下条件
\[f^{\prime}(x)=0 \Longrightarrow f^{\prime \prime}(x) \geqslant 0,\]上述条件隐含的意思是:对于凸函数,每一个点都要是半正定的才算凸函数;但是对于拟凸函数,只要在关键点($\nabla f(x)=0$)处,$\nabla^{2}f(x)$半正定就是拟凸函数(充分必要条件)。
2.5 对数-凹函数和对数-凸函数
称函数 $f: \mathbf{R}^{n} \rightarrow \mathbf{R}$ 对数凹或对数-凹, 如果对所有的 $x \in \operatorname{dom} f$ 有 $f(x)>0$ 且 $\log f$ 是凹函数。称函数对数凸或者对数-凸, 如果 $\log f$ 是凸函数。
若 $f$ 为对数凸,则 $f$ 一定是凸函数(对数凸函数更强);若函数是对数凹函数,不一定是凹函数;若函数是凹函数,一定是对数凹(凹函数更强)。(复合函数去证明)
3 凸优化
3.1 凸优化问题
广义:凸目标、凸集约束
一般优化问题的描述:
\[\begin{array}{ll} \operatorname{minimize} & f_{0}(x) \\ \text { subject to } & f_{i}(x) \leqslant 0, \quad i=1, \cdots, m \\ & h_{i}(x)=0, \quad i=1, \cdots, p \end{array}\]描述在所有满足 $f_{i}(x) \leqslant 0, i=1, \cdots, m$ 及 $h_{i}(x)=0, i=1, \cdots, p$ 的 $x$ 中寻找极小化 $f_{0}(x)$ 的 $x$ 的问题。我们称 $x \in \mathbf{R}^{n}$ 为优化变量(optimization variable), 称函数 $f_{0}: \mathbf{R}^{n} \rightarrow \mathbf{R}$ 为目标函数(objective function)或者损失函数(cost function)或者效用函数(utility function)。不等式 $f_{i}(x) \leqslant 0$ 称为不等式约束(inequality constraint), 相应的函数 $f_{i}: \mathbf{R}^{n} \rightarrow \mathbf{R}$ 称为不等式约束函数。方程组 $h_{i}(x)=0$ 称为等式约束(equality constraint), 相应的函数 $h_{i}: \mathbf{R}^{n} \rightarrow \mathbf{R}$ 称为等式约束函数。 如果没有约束(即 $m=p=0$),我们称问题为无约束问题(unconstrained)。优化问题的域(domain):$\mathcal{D}=\bigcap_{i=0}^{m} \operatorname{dom} f_{i} \cap \bigcap_{i=1}^{p} \operatorname{dom} h_{i},$。当点满足约束时称为可行点,当问题至少有一个可行点时,我们称为可行的,否则称为不可行。所有可行点的集合称为可行集或约束集。
问题的最优值(optimal value):
\[p^{\star}=\inf \{f_{0}(x) \mid f_{i}(x) \leq 0, i=1, \ldots, m, h_{i}(x)=0, i=1, \ldots, p\}\]当不存在可行点时,原问题不可行,$p^{\star}=\infty$,意思时问题不能有效地极小化。如果存在可行解 $x_{k}$ 满足: 当 $k \rightarrow \infty$ 时,
\[f_{0}\left(x_{k}\right) \rightarrow-\infty\]那么, $p^{\star}=-\infty$ 并且我们称问题无下界。
最优解(optimal point/solution):若 $x^{\star}$ 可行,且 $f_0(x^\star)=p^{\star}$。
最优解集(optimal set):
\[X_{\mathrm{opt}}=\{x \mid f_{i}(x) \leqslant 0, i=1, \cdots, m, h_{i}(x)=0, i=1, \cdots, p, f_{0}(x)=p^\star \}\]如果问题存在最优解, 我们称最优值是可得或可达的, 称问题可解。如果 $X_{\mathrm{opt}}$ 是空集, 我们称最优值是不可得或不可达的 (这种情况常在问题无下界时发生)。满足 $f_{0}(x) \leqslant p^{\star}+\epsilon$ (其中 $\epsilon>0$ )的可行解 $x$ 称为 $\epsilon$ -次优。所有 $\epsilon$ -次优解的集合称为问 题 $(4.1)$ 的 $\epsilon$ -次优集。
$\epsilon$ 次优解集($\epsilon$-suboptimal set):satisficing solutions(satisficing由satisfy和suffice组成),足够满意的解。满足 $f_{0}(x) \leqslant p^{\star}+\epsilon$ (其中 $\epsilon>0$ )的可行解 $x$ 称为 $\epsilon$ -次优。所有 $\epsilon$ -次优解的集合称为问题的 $\epsilon$ -次优集。
我们称可行解 $x$ 为局部最优(locally optimal), 如果存在 $R>0$ 使得
\[\begin{aligned} f_{0}(x)=& \inf \left\{f_{0}(z) \mid f_{i}(z) \leqslant 0, i=1, \cdots, m,\right.\\ &\left.h_{i}(z)=0, i=1, \cdots, p,\|z-x\|_{2} \leqslant R\right\} \end{aligned}\]即 $x$ 在可行集内一个点的周围极小化了 $f_{0}$。
如果 $x$ 可行且 $f_{i}(x)=0$, 我们称约束 $f_{i}(x) \leqslant 0$ 的第 $i$ 个不等式在 $x$ 处起作用。 如果 $f_{i}(x)<0$, 则约束 $f_{i}(x) \leqslant 0$ 不起作用。(对于所有可行解, 等式约束总是起作用 的。)我们称约束是冗余的, 如果去掉它不改变可行集。
可行性问题:
如果目标函数恒等于零, 那么其最优解要么是零 (如果可行集非空), 要么是 $\infty$ (如 果可行集是空集)。我们称其为可行性问题, 有些时候将其写作
因此,可行性问题可以用来判断约束是否一致, 如是, 则找到一个满足它们的点。
问题的标准表示:
将问题表示成下述形式:
等价问题:
作为一个简单例子,考虑问题
通过乘以正的常数,原问题与现问题的解是相同的,即两个问题等价。
下面介绍一些产生等价问题的变换:
1. 变量变换
设 $\phi: \mathbf{R}^{n} \rightarrow \mathbf{R}^{n}$ 是一一映射, 其象包含了问题的定义域 $\mathcal{D}$, 即 $\phi(\operatorname{dom} \phi) \supseteq \mathcal{D}$ 。我们定义函数 $\tilde f_{i}$ 和 $\tilde h_{i}$ 为
\[\tilde{f}_{i}(z)=f_{i}(\phi(z)), \quad i=0, \cdots, m, \quad \tilde{h}_{i}(z)=h_{i}(\phi(z)), \quad i=1, \cdots, p\]原来关于变量 $x$ 的问题转化为关于变量 $z$ 的问题
\[\begin{array}{ll} \operatorname{minimize} & \tilde{f}_{0}(z) \\ \text { subject to } & \tilde{f}_{i}(z) \leqslant 0, \quad i=1, \cdots, m \\ & \tilde{h}_{i}(z)=0, \quad i=1, \cdots, p, \end{array}\]两个问题之间通过变量代换 $x=\phi(z)$ 所联系。
2. 目标函数和约束函数的变换
设 $\psi_{0}: \mathbf{R} \rightarrow \mathbf{R}$ 单增; $\psi_{1}, \cdots, \psi_{m}: \mathbf{R} \rightarrow \mathbf{R}$ 满足:当且仅当 $u \leqslant 0$ 时 $\psi_{i}(u) \leqslant 0 $;$ \psi_{m+1}, \cdots, \psi_{m+p}: \mathbf{R} \rightarrow \mathbf{R}$ 满足:当且仅当 $u=0$ 时 $\psi_{i}(u)=0$ 。我们定义函数 $\tilde f_i $ 和 $\tilde h_{i} $ 为复合函数
\[\tilde{f}_{i}(x)=\psi_{i}\left(f_{i}(x)\right), \quad i=0, \cdots, m, \quad \tilde{h}_{i}(x)=\psi_{m+i}\left(h_{i}(x)\right), \quad i=1, \cdots, p\]3. 消除等式约束
如果我们可以用一些参数 $z \in \mathbf{R}^{k}$ 来显式地参数化等式约束
\[h_{i}(x)=0, \quad i=1, \cdots, p\]的解, 那么我们可以从原问题中消除等式约束, 如下所示。设函数 $ \phi:\mathbf R^{k} \rightarrow \mathbf R^{n}$ 是这样的函数: $x$ 满足式 $(4.8)$ 等价于存在一些 $z \in \mathbf{R}^{k}$ 使得 $x=\phi(z)$ 。那么, 优化问题
\[\begin{array}{ll} \operatorname{minimize} & \tilde{f}_{0}(z)=f_{0}(\phi(z)) \\ \text { subject to } & \tilde{f}_{i}(z)=f_{i}(\phi(z)) \leqslant 0, \quad i=1, \cdots, m \end{array}\]与原问题等价。转换后的问题含有变量 $z \in \mathbf{R}^{k}, m$ 个不等式约束而没有等式约束。如果 $z$ 是转换后问题的最优解, 那么 $x=\phi(z)$ 是原问题的最优解。反之, 如果 $x$ 是原问题的最优解, 那么(因为 $x$ 是可行解)存在至少一个 $z$ 使得 $x=\phi(z)$ 。任意这样的 $z$ 均是转换后的问题的最优解。
3.2 凸优化
狭义凸优化问题
凸优化问题是形如:
\[\begin{array}{ll} \operatorname{minimize} & f_{0}(x)\\ \text { subject to } & f_{i}(x) \leqslant 0, \quad i=1, \cdots, m \\ & a_{i}^{T} x=b_{i}, \quad i=1, \cdots, p \end{array}\]的问题, 其中 $f_{0}, \cdots, f_{m}$ 为凸函数。对比问题 $(4.15)$ 和一般的标准形式问题(4.1), 凸优化问题有三个附加的要求:
- 目标函数必须是凸的,
- 不等式约束函数必须是凸的,
- 等式约束函数 $h_{i}(x)=a_{i}^{T} x-b_{i}$ 必须是仿射的。
凸优化问题的局部最优点就是全局最优点。
可微函数 $f_0$ 的最优性准则
设凸优化问题的目标函数 $f_{0}$ 是可微的, 对于所有的 $x, y \in \operatorname{dom} f_{0}$ 有
\[f_{0}(y) \geqslant f_{0}(x)+\nabla f_{0}(x)^{T}(y-x)\]令 $X$ 表示可行集,当且仅当 $x \in X$ 且 $\nabla f_{0}(x)^{T}(y-x) \geqslant 0, \forall y \in X$ 时,$x$ 是最优解。
非负象限中的极小化
\[\begin{array}{ll} \text { minimize } & f_{0}(x) \\ \text { subject to } & x \succeq 0 \end{array}\]于是最优性条件为
\[x \succeq 0, \quad \nabla f_{0}(x)^{T}(y-x) \geqslant 0, \forall y \succeq 0\]可以转换为
\[x \succeq 0, \quad \nabla f_{0}(x) \succeq 0, \quad x_{i}\left(\nabla f_{0}(x)\right)_{i}=0, \quad i=1, \cdots, n\]最后一个条件称为互补条件。
拟凸优化
\[\begin{array}{ll} \operatorname{minimize} & f_{0}(x) \\ \text { subject to } & f_{i}(x) \leqslant 0, \quad i=1, \cdots, m \\ & A x=b \end{array}\]其中, 不等式约束函数 $f_{1}, \cdots, f_{m}$ 是凸的, 而目标函数 $f_{0}$ 是拟凸的。
极大化凹函数是凸优化问题。
3.3 线性规划问题
线性规划(Linear Program)
\[\begin{array}{ll} \operatorname{minimize} & c^{T} x+d \\ \text { subject to } & G x \preceq h \\ & A x=b, \end{array}\]其中 $G \in \mathbf{R}^{m \times n}, A \in \mathbf{R}^{p \times n}$ 。当然, 线性规划是凸优化问题。(线性规划也有动词意思,Linear Programming)
线性规划的不等式形式:
如果线性规划问题没有等式约束,则称为不等式形式线性规划:
\[\begin{array}{ll} \operatorname{minimize} & c^{T} x \\ \text { subject to } & A x \preceq b \end{array}\]线性规划的标准形式:
\[\begin{array}{ll} \operatorname{minimize} & c^{T} x \\ \text { subject to } & A x=b \\ & x \succeq 0 \end{array}\]转换为标准形式方法:
- 引入松弛变量 $s$,得到
- 将变量 $x$ 表示为两个非负变量($x^+$和$x^-$,$x^+,x^- \succeq 0$)的差,得到:
标准形式与原问题等价。
证明两个问题等价方法
- 对于最优化问题,一个方法是证明问题一的最优解和问题二的最优解是一一对应的(问题一的最优解能推出问题二的最优解,问题二的最优解能推出问题一的最优解),且最优值相同。
- 另一个方法是证明问题一和问题二各自的变量都有一一对应关系,问题一的变量如果在问题一是可行的,在问题二中,对应的变量也应该是可行的。且此时各自的目标函数值相同。同理,正着反着都要验证一遍,即由问题一推出问题二,由问题二推出问题一。
线性分式规划:
线性分式规划可以写为:
\[\begin{array}{ll} \operatorname{minimize} & f_{0}(x) \\ \text { subject to } & G x \preceq h \\ & A x=b, \end{array}\]其目标函数由
\[f_{0}(x)=\frac{c^{T} x+d}{e^{T} x+f}, \quad \operatorname{dom} f_{0}=\left\{x \mid e^{T} x+f>0\right\}\]给出。这个目标函数是拟凸的,因此是个拟凸优化问题。
转换为线性规划
如果可行集
\[\left\{x \mid G x \preceq h, A x=b, e^{T} x+f>0\right\}\]非空, 线性分式规划可以转换为等价的线性规划
\[\begin{array}{ll} \operatorname{minimize} & c^{T} y+d z \\ \text { subject to } & G y-h z \preceq 0 \\ & A y-b z=0 \\ & e^{T} y+f z=1 \\ & z \geqslant 0, \end{array}\]其优化变量为 $y, z$,$y=\frac{x}{e^{T} x+f}, \quad z=\frac{1}{e^{T} x+f}$
3.4 二次规划(Quadratic programming)问题
QP问题的目标函数是凸二次型,约束函数是仿射函数:
\[\begin{array}{ll} \operatorname{minimize} & (1 / 2) x^{T} P x+q^{T} x+r \\ \text { subject to } & G x \preceq h \\ & A x=b \end{array}\]其中 $P \in \mathbf{S}_{+}^{n}, G \in \mathbf{R}^{m \times n}$ 并且 $A \in \mathbf{R}^{p \times n}$。
如果约束也是凸二次型,则该问题称为二次约束二次规划(QCQP)。
一范数规范化的最小二乘(LASSD)
若 $x$ 稀疏,则对 $x$ 的估计可以加上$ \Vert x \Vert _1$ 项,使得 $x$ 的估计 $\hat x =\operatorname{argmin}_x \ \Vert b-Ax \Vert _2^2$ 尽可能小:
\[\hat x =\operatorname{argmin}_x \ \Vert b-Ax \Vert _2^2+ \lambda _1 \Vert x \Vert _1\]解上述问题的一个常用方法:
可以设 $x=x^+-x^-,x^+,x^- \geq 0$。
例如,
原始表达式可以表示为
\[\begin{array}{ll} \operatorname{argmin}_{x^+,x^-} \Vert b-Ax^+ + Ax^- \Vert _2^2+\lambda _1 \Vert x^+ - x^- \Vert _1\\ = \operatorname{argmin}_{x^+,x^-} \Vert b-Ax^+ + Ax^- \Vert _2^2+\lambda _1 1^Tx^+ + \lambda _1 1^T x^- \end{array}\]通过以上方法,去掉了绝对值,原始凸函数转换为了凸二次型。
二范数规范化的最小二乘(岭回归)
若 $x$ 中元素幅度类似,则对 $x$ 的估计可以加上 $ \Vert x \Vert _2^2$ 项,使得元素彼此之间更接近:
\[\hat x =\operatorname{argmin}_x \ \Vert b-Ax \Vert _2^2+ \lambda _2 \Vert x \Vert _2^2\]该问题是二次规划问题,二次项对应的正定矩阵为 $A^T A+ \lambda I$ 。
可以证明:上述式子和下面QCQP问题等价:
\[\begin{array}{ll} \hat x =\operatorname{argmin}_x \ \Vert b-Ax \Vert _2^2 \\ \operatorname{s.t.} \ \Vert x \Vert _2^2 \leq 0 \end{array}\]3.5 半定规划
半定规划(Semi-Definite Programming):
标准形式的SDP:
\[\begin{array}{ll} \operatorname{minimize} & \operatorname{tr}(C X) \\ \text { subject to } & \operatorname{tr}\left(A_{i} X\right)=b_{i}, \quad i=1, \cdots, p \\ & X \succeq 0 \end{array}\]其中 $C,X, A_{1}, \cdots, A_{p} \in \mathbf{S}^{n}$ 。(注意 $\operatorname{tr}(C X)=\sum_{i, j=1}^{n} C_{i j} X_{i j}$ 是 $\mathbf{S}^{n}$ 上一般实值线性函数的形式。)和线性规划的标准形式一致,我们在变量的 $p$ 个线性等式约束和变量非负约束下极小化变量的线性函数。
不等式形式的SDP:
\[\begin{array}{ll} \operatorname{minimize} & c^{T} x \\ \text { subject to } & x_{1} A_{1}+\cdots+x_{n} A_{n} \preceq B \end{array}\]其优化变量为 $x \in \mathbf{R}^{n}$, 参数为 $B, A_{1}, \cdots, A_{n} \in \mathbf{S}^{k}, c \in \mathbf{R}^{n}$。
矩阵的二范数是矩阵的转置与矩阵的积的最大奇异值的算数平方根,关于二范数的一个结论:
\[\Vert A(x) \Vert _2 \leq \sqrt S, S > 0 \longleftrightarrow A^T(x)A(x)-S I \preceq 0\]例子:
\[\begin{array}{ll} \operatorname{minimize} & \Vert A(x) \Vert _2 \\ \operatorname{subject to} &A(x)=A_0+x_1 A_1 +\cdots+x_n A_n \\ & A_i \in R^ {p \times g},i=0,\cdots,n,x \in R^{n} \end{array}\]上述问题等价于:
\[\begin{array}{ll} \operatorname{minimize} & \sqrt{S} \\ \operatorname{subject to} & A^T(x) A(x) \preceq S I \\ \end{array}\]$A^T(x)A(x)$ 关于 $x$ 是凸函数。$SI$ 关于 $S$ 是线性函数,所以$A^T(x)A(x)-SI$ 关于 $S,x$ 是联合凸的。
利用
\[A^{T} A \preceq t^{2} I(\text { 并且 } t \geqslant 0) \Longleftrightarrow\left[\begin{array}{ll} t I & A \\ A^{T} & t I \end{array}\right] \succeq 0\]的事实, 我们也可以用一个大小为 $(p+q) \times(p+q)$ 的矩阵不等式对问题进行构建。其结果是关于变量 $x$ 和 $t$ 的 SDP
\[\begin{array}{ll} \operatorname{minimize} & t \\ \text { subject to } & {\left[\begin{array}{cc} t I & A(x) \\ A(x)^{T} & t I \end{array}\right] \succeq 0} \end{array}\]3.6 多目标优化问题
$f_0$ 不再是单一的标量了,变成了向量,$f_0$ 的分量,即 $F_1,\cdots,F_q$,可以解释为 $q$ 个不同的标量目标,每一个都希望被极小化。如果不等式约束函数是凸的,等式约束函数是仿射的,$F_1,\cdots,F_q$是凸的,我们称多目标问题是凸的。
如果 $x$ 和 $y$ 都可行, 对于 $i=1, \cdots, q$ 都有 $F_{i}(x) \leqslant F_{i}(y)$,并且对于至少一个 $j$, 有 $F_{j}(x)<F_{j}(y)$, 我们称 $x$ 比 $y$ 更优, 或 $x$ 支配 $y$ 。
在多准则问题中, 最优解 $x^{\star}$ 满足: 对于可行的 $y$ 都有
\[F_{i}\left(x^{\star}\right) \leqslant F_{i}(y), \quad i=1, \cdots, q\]换言之, $x^{\star}$ 同时是下述所有 $j=1, \cdots, q$ 标量优化问题的最优解,
\[\begin{array}{ll} \operatorname{minimize} & F_{j}(x) \\ \text { subject to } & f_{i}(x) \leqslant 0, \quad i=1, \cdots, m \\ & h_{i}(x)=0, \quad i=1, \cdots, p \end{array}\]Pareto 最优解与值:
帕累托最优面(Pareto optimal front):任意点,若域内有另一点在某个指标上更好,必在另一个指标上更差。
帕累托最优值:帕累托最优面上一点所对应的值。
帕累托最优点:帕累托最优面上的一个点。
 横坐标是经济发展速度,纵坐标是发展质量,弧线是Pareto最优面。
横坐标是经济发展速度,纵坐标是发展质量,弧线是Pareto最优面。
标量化:
若 $\{ f_0(x) \}$ 在 $R^k$ 中为凸,$f_i(x)$ 为凸,$h_i(x)$ 为仿射,则必可通过下述方法求得Pareto最优面中一个点(注意不是所有点都能求出来)。
\[\begin{array}{ll} \operatorname{minimize} & \lambda^{T} f_{0}(x) \\ \text { subject to } & f_{i}(x) \leqslant 0, \quad i=1, \cdots, m \\ & h_{i}(x)=0, \quad i=1, \cdots, p \end{array}\]关联性:
举一个例子说明多目标优化,单目标优化和带约束优化的关联性:
- 多目标优化,$\operatorname{minimize} \Vert b-Ax \Vert _2^2,\Vert x \Vert _2^2$
- 岭回归,$\operatorname{minimize} \Vert b-Ax \Vert _2^2 +\lambda \Vert x \Vert _2^2$
- 带约束优化,
 上述三个问题互相等价,不仅多优化问题可以通过标量化转化为单目标优化问题,带约束的优化问题也可以转化为单目标优化问题,这需要用到对偶原理。
上述三个问题互相等价,不仅多优化问题可以通过标量化转化为单目标优化问题,带约束的优化问题也可以转化为单目标优化问题,这需要用到对偶原理。
4 对偶
4.1 Lagrange 对偶函数
标准形式的优化问题:
\[\begin{array}{ll} \operatorname{minimize} & f_{0}(x) \\ \text { subject to } & f_{i}(x) \leqslant 0, \quad i=1, \cdots, m \\ & h_{i}(x)=0, \quad i=1, \cdots, p \end{array}\]定义域:$\mathcal{D}=\bigcap_{i=0}^{m} \operatorname{dom} f_{i} \cap \bigcap_{i=1}^{p} \operatorname{dom} h_{i}$,优化问题的最优值为 $p^{\star}$。不一定是凸优化问题。
Lagrange 函数$L: \mathbf{R}^{n} \times \mathbf{R}^{m} \times \mathbf{R}^{p} \rightarrow \mathbf{R}$ 为:
\[L(x, \lambda, \nu)=f_{0}(x)+\sum_{i=1}^{m} \lambda_{i} f_{i}(x)+\sum_{i=1}^{p} \nu_{i} h_{i}(x)\]其中定义域为 $\operatorname{dom} L=\mathcal{D} \times \mathbf{R}^{m} \times \mathbf{R}^{p}$。$\lambda_{i}$ 称为第 $i$ 个不等式约束 $f_{i}(x) \leqslant 0$ 对应的 Lagrange 乘子; 类似地, $\nu_{i}$ 称为第 $i$ 个等式约束 $h_{i}(x)=0$ 对应的 Lagrange 乘子。 向量 $\lambda$ 和 $\nu$ 称为对偶变量或者是问题的 Lagrange 乘子向量。
Lagrange 对偶的基本思想是在目标函数中引入约束条件的加权和,得到增广的目标函数。
Larange 对偶函数
定义 Lagrange对偶函数(或对偶函数) $g: \mathbf{R}^{m} \times \mathbf{R}^{p} \rightarrow \mathbf{R}$ 为 Lagrange 函数关于 $x$ 取得的最小值:即对 $\lambda \in \mathbf{R}^{m}, \nu \in \mathbf{R}^{p}$, 有
\[g(\lambda, \nu)=\inf _{x \in \mathcal{D}} L(x, \lambda, \nu)=\inf _{x \in \mathcal{D}}\left(f_{0}(x)+\sum_{i=1}^{m} \lambda_{i} f_{i}(x)+\sum_{i=1}^{p} \nu_{i} h_{i}(x)\right)\]$g$ 是关于 $\lambda$ 和 $\nu$ 的线性函数,根据逐点下确界的性质,即使原问题不是凸函数,对偶函数是凹函数。
最优值的下界:
原问题的最优值为 $p^{\star}$,下面关系成立:
对任意$\lambda \succeq 0$ 和 $\nu$ 下式成立
对 Lagrange 对偶的理解

 Lagrange 对偶只能给出最优值的下界。
Lagrange 对偶只能给出最优值的下界。
数形结合理解 KKT 条件
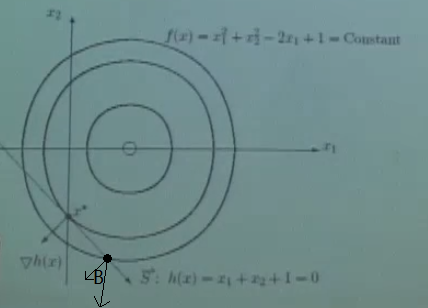
对于 KKT 中的等式约束,其法线方向必须与目标函数的梯度方向在同一条线上,否则一定存在上图的 B 点,其等式约束(直线)的法方向和函数(圆)的法方向所夹是锐角,因此从 B 出发沿着直线的方向,其后的点都在增大。所以对于最优点,一定有法线方向必须与目标函数的梯度方向在同一条线上的结论成立。
上述等式约束是线性的,再举一个非线性的例子:
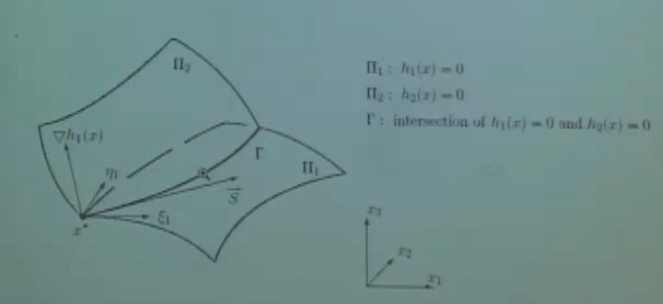 $\Pi _1$ 和 $\Pi _2$ 的交线是非线性的,构成了一个问题的等式约束。曲线 $\Gamma$ 在 $x^{\star}$ 处的法方向必须与目标函数在 $x^{\star}$ 处的法方向在同一直线上。又因为 $\Pi _1,\Pi _2$ 在 $x^{\star}$ 处的法方向垂直于 $\Gamma$ 的法方向,所以 $\Pi _1,\Pi _2$ 在 $x^{\star}$ 处的法方向一定与目标函数在 $x^{\star}$ 处的法方向相同。即
$\Pi _1$ 和 $\Pi _2$ 的交线是非线性的,构成了一个问题的等式约束。曲线 $\Gamma$ 在 $x^{\star}$ 处的法方向必须与目标函数在 $x^{\star}$ 处的法方向在同一直线上。又因为 $\Pi _1,\Pi _2$ 在 $x^{\star}$ 处的法方向垂直于 $\Gamma$ 的法方向,所以 $\Pi _1,\Pi _2$ 在 $x^{\star}$ 处的法方向一定与目标函数在 $x^{\star}$ 处的法方向相同。即
显然 $\nu$ 可以取到正负。这就是只带等式约束的稳定性条件的几何解释。
注意,拉格朗日的解不存在不一定意味着原问题的解不存在。
例子:
\[\begin{array}{lc} \max &f(x)=f\left(x_{1}, x_{2}\right)=20 x_{1}+10 x_{2} \\ \text{s.t.} & \begin{align} x_1^{2}+x_2 ^2 & \leq 1 \\ x_{1}+2 x_{2} & \leq 2 \\ x_{1}, x_{2} & \geq 0 . \end{align} \end{array}\]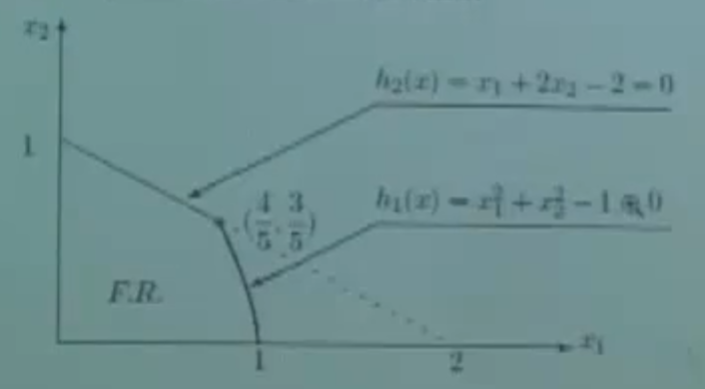
内点的梯度方向
\[\nabla f(x)=\left\{\begin{array}{l} \frac{\partial f}{\partial x_{1}} \\ \frac{\partial f}{\partial x_{2}} \end{array}\right\}=\left\{\begin{array}{l} 20 \\ 10 \end{array}\right\} \neq 0 .\]解不等于0,所以最优点一定不在内部(因为不满足最优性条件)。
因此一定在上图的四段边界中,
\[h_{1}(x)=x_{1}^{2}+x_{2}^{2}-1=0 , \quad \nabla h(x)=\left\{\begin{array}{l} 2 x_{1} \\ 2 x_{2} \end{array}\right\}\] \[h_{2}(x)=x_{1}+2 x_{2}-2=0, \quad \nabla h(x)=\left\{\begin{array}{c} 1 \\ 2 \end{array}\right\} \neq \lambda \nabla f(x)\] \[h_{3}(x)=-x_{1}=0, \quad \nabla h(x)=\left\{\begin{array}{c} -1 \\ 0 \end{array}\right\} \neq \lambda \nabla f(x)\] \[h_{4}(x)=-x_{2}=0, \quad \nabla h(x)=\left\{\begin{array}{c} 0 \\ -1 \end{array}\right\} \neq \lambda \nabla f(x)\]所以,上述约束中唯一起作用的就是 $h_1$ 约束,即
\[\nabla f(x)=\lambda \nabla h_{1}(x)\] \[\left\{\begin{array}{l} 2 x_{1} \\ 2 x_{2} \end{array}\right\}=\lambda\left\{\begin{array}{c} 20 \\ 10 \end{array}\right\}\] \[x=\left\{\begin{array}{c} x_{1} \\ x_{2} \end{array}\right\}=\frac{1}{\sqrt{5}}\left\{\begin{array}{c} 2 \\ 1 \end{array}\right\}, \quad \lambda=\frac{1}{5 \sqrt{5}}\]对于不等式约束,
\[f_i(x) \leq 0,i=1,2,\cdots,m\]真正起作用的只有一部分 $f_i(x)=0$,其他不等式约束对限制最优解不起到作用。(注意对于起作用的约束,小于等于变为等于)
共轭函数:
函数 $f: \mathbf{R}^{n} \rightarrow \mathbf{R}$ 的共轭函数 $f^{*}$ 为
\[f^{*}(y)=\sup _{x \in \operatorname{dom} f}\left(y^{T} x-f(x)\right)\]4.2 Lagrange 对偶问题
Lagrange 对偶问题可以表述为求原问题的最好下界:
\[\begin{array}{ll} \operatorname{maximize} & g(\lambda, \nu) \\ \text { subject to } & \lambda \succeq 0 \end{array}\]对偶可行:满足 $\lambda \succeq 0$ 和 $g(\lambda, \nu)>-\infty$ 的一组 $(\lambda, \nu)$, 此时具有意义。这样的一组 $(\lambda, \nu)$ 是对偶问题的一个可行解。
最优Lagrange乘子:称解 $\left(\lambda^{\star}, \nu^{\star}\right)$ 是对偶最优解或者是最优 Lagrange 乘子, 如果它是对偶问题的最优解。
Lagrange问题是一个凸优化问题,因为极大化凹函数即为极小化凸函数,对偶问题的凸性与原问题是否是凸优化问题无关。
标准形式线性规划
\[\begin{array}{ll} \operatorname{minimize} & c^{T} x \\ \text { subject to } & A x=b \\ & x \succeq 0 \end{array}\]Lagrange对偶函数为
\[g(\lambda, \nu)=\left\{\begin{array}{cl} -b^{T} \nu & A^{T} \nu-\lambda+c=0 \\ -\infty & \text { 其他情况 } \end{array}\right.\]对偶问题:
\[\begin{array}{ll} \operatorname{ maximize } & g(\lambda, \nu)=\left\{\begin{array}{cl} -b^{T} \nu & A^{T} \nu-\lambda+c=0 \\ -\infty & \text { 其他情况 } \end{array}\right. \\ \operatorname{ subject to } & \quad \lambda \succeq 0 . \end{array}\]当且仅当 $A^{T} \nu-\lambda+c=0$ 时对偶函数 $g$ 有界。我们可以通过将此“隐含”的等式约束“显式”化来得到一个等价的问题
\[\begin{array}{ll} \operatorname{maximize} & -b^{T} \nu \\ \text { subject to } & A^{T} \nu-\lambda+c=0 \\ & \lambda \succeq 0 \end{array}\]进一步地, 这个问题可以表述为不等式形式的线性规划
\[\begin{array}{l} \text { maximize } \quad-b^{T} \nu\\ \text { subject to } A^{T} \nu+c \succeq 0 \end{array}\]不等式形式线性规划
\[\begin{array}{ll} \operatorname{minimize} & c^{T} x \\ \text { subject to } & A x \preceq b \end{array}\]对偶函数
\[g(\lambda)=\left\{\begin{array}{cl} -b^{T} \lambda & A^{T} \lambda+c=0 \\ -\infty & \text { 其他情况 } \end{array}\right.\]对偶问题
\[\begin{array}{ll} \operatorname{maximize} & -b^{T} \lambda \\ \text { subject to } & A^{T} \lambda+c=0 \\ & \lambda \succeq 0 \end{array}\]可以化简为
\[\begin{array}{ll} \operatorname{minimize} & b^{T} \lambda \\ \operatorname{ subject to } & A^{T} \lambda+c=0 \\ & \lambda \succeq 0 \end{array}\]标准形式的线性规划和不等式形式的线性规划以及它们的对偶问题之间有对称性:标准形式线性规划的对偶问题是只含有不等式约束的线性规划问题,反之亦然。
弱对偶性:
Lagrange 对偶问题的最优值,用 $d^{\star}$ 表示,这是原问题最优值 $p^{\star}$ 的最好下界:
\[d^{\star} \leqslant p^{\star}\]该性质称为弱对偶性。定义差值 $p^{\star}-d^{\star}$ 是原问题的最优对偶间隙。
强对偶性:
如果等式
\[d^{\star}=p^{\star}\]成立, 即最优对偶间隙为零, 那么强对偶性成立。
$\mathcal{D}$ 的相对内部,记为 relint $\mathcal{D}$,$\mathcal{D}=\{ x \in \mathcal{D} \mid B(x,r) \cap aff \mathcal{D} \subset \mathcal{D},\exists r > 0 \}$。粗略理解,相对内部就是去掉边界的开集。
Slater 条件
若有凸问题,
\[\begin{array}{ll} \operatorname{minimize} & f_{0}(x) \\ \text { subject to } & f_{i}(x) \leqslant 0, \quad i=1, \cdots, m, \\ & A x=b \end{array}\]存在一点 $x \in \operatorname{relint} \mathcal{D}$ 使得下式成立
\[f_{i}(x)<0, \quad i=1, \cdots, m, \quad A x=b\]Slater 定理说明, 当 Slater 条件成立时,强对偶性成立,即存在一组对偶可行解 $\left(\lambda^{\star}, \nu^{\star}\right)$ 使得 $g\left(\lambda^{\star}, \nu^{\star}\right)=d^{\star}=p^{\star}$。
弱Slater 条件:
若不等式约束为仿射时,只要可行域非空,必有 $p^{\star}=d^{\star}$。
所以线性规划问题,一定满足强对偶性。
对偶问题等价,原问题不一定等价。
4.3 几何解释
- 通过函数值集合理解强弱对偶性
假设
\[\mathcal{G}=\left\{\left(f_{1}(x), \cdots, f_{m}(x), h_{1}(x), \cdots, h_{p}(x), f_{0}(x)\right) \in \mathbf{R}^{m} \times \mathbf{R}^{p} \times \mathbf{R} \mid x \in \mathcal{D}\right\}\]优化问题的最优值 $p^{\star}$
\[p^{\star}=\inf \{t \mid(u, v, t) \in \mathcal{G}, u \preceq 0, v=0\}\]Lagrange 函数:
\[(\lambda, \nu, 1)^{T}(u, v, t)=\sum_{i=1}^{m} \lambda_{i} u_{i}+\sum_{i=1}^{p} \nu_{i} v_{i}+t\]对偶函数:
\[g(\lambda, \nu)=\inf \left\{(\lambda, \nu, 1)^{T}(u, v, t) \mid(u, v, t) \in \mathcal{G}\right\}\]假设 $\lambda \succeq 0$ 。显然, 如果 $u \preceq 0$ 且 $v=0$, 则成立 $t \geqslant(\lambda, \nu, 1)^{T}(u, v, t)$ 。 因此有
\[\begin{aligned} p^{\star} &=\inf \{t \mid(u, v, t) \in \mathcal{G}, u \preceq 0, v=0\} \\ & \geqslant \inf \left\{(\lambda, \nu, 1)^{T}(u, v, t) \mid(u, v, t) \in \mathcal{G}, u \preceq 0, v=0\right\} \\ & \geqslant \inf \left\{(\lambda, \nu, 1)^{T}(u, v, t) \mid(u, v, t) \in \mathcal{G}\right\} \\ &=g(\lambda, \nu) \end{aligned}\]即弱对偶性成立。
针对只有一个不等式约束的简单问题:
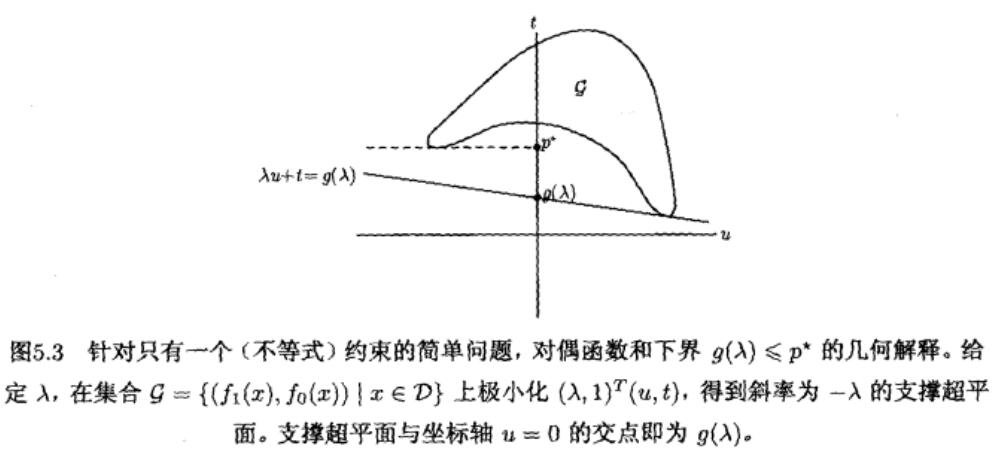
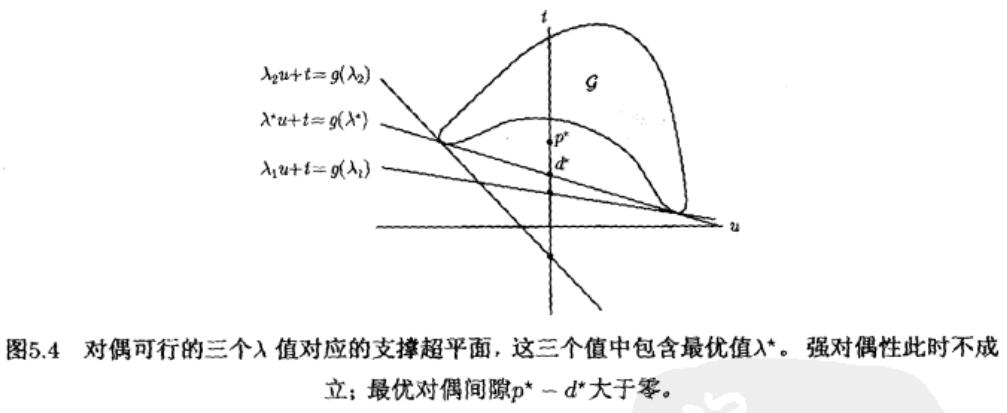
- 鞍点解释
假设没有等式约束,可以证明下式成立
\[\begin{aligned} \sup _{\lambda \succeq 0} L(x, \lambda) &=\sup _{\lambda \succeq 0}\left(f_{0}(x)+\sum_{i=1}^{m} \lambda_{i} f_{i}(x)\right) \\ &=\left\{\begin{array}{ll} f_{0}(x) & f_{i}(x) \leqslant 0, \quad i=1, \cdots, m \\ \infty & \text { 其他情况 } \end{array}\right. \end{aligned}\]所以原问题的最优值可以写成
\[p^{\star}=\inf _{x} \sup _{\lambda \succeq 0} L(x, \lambda)\]根据对偶函数的定义, 有
\[d^{\star}=\sup _{\lambda \succeq 0} \inf _{x} L(x, \lambda) .\]所以弱对偶性可以表述为下述不等式
\[\sup _{\lambda \succeq 0} \inf _{x} L(x, \lambda) \leqslant \inf _{x} \sup _{\lambda \succeq 0} L(x, \lambda)\]强对偶性可以表示为下面的不等式
\[\sup _{\lambda \succeq 0} \underset{x}{\inf } L(x, \lambda)=\inf _{x} \sup _{\lambda \succeq 0} L(x, \lambda)\]事实上,对任意 $f: \mathbf{R}^{n} \times \mathbf{R}^{m} \rightarrow \mathbf{R}$(以及任意 $W \subseteq \mathbf{R}^{n}$ 和 $Z \subseteq \mathbf{R}^{m}$),下式成立:
\[\sup _{z \in Z} \inf _{w \in W} f(w, z) \leqslant \inf _{w \in W} \sup _{z \in Z} f(w, z)\]这个一般的不等式称为极大极小不等式。若等式成立,我们称 $f$ (以及 $W$ 和 $Z$ )满足强极大极小性质或者鞍点性质。
我们称一对 $\tilde{w} \in W, \tilde{z} \in Z$ 是函数 $f$ (以及 $W$ 和 $Z$ ) 的鞍点, 如果对任意 $w \in W$ 和 $z \in Z$ 下式成立
\[f(\tilde{w}, z) \leqslant f(\tilde{w}, \tilde{z}) \leqslant f(w, \tilde{z})\]上式意味着强极大极小性质成立, 且共同值为 $f(\tilde{w}, \tilde{z})$ 。
鞍点定理:如果 $x^{\star}$ 和 $\lambda^{\star}$ 分别是原问题和对偶问题的最优点, 且强对偶性成立, 则它们是 Lagrange 函数的一个鞍点。反过来同样成立: 如果 ( $x, \lambda$ ) 是 Lagrange 函数的一个鞍点, 那么 $x$ 是原问题的最优解, $\lambda$ 是对偶问题的最优解, 且最优对偶间隙为零。
上面两条可以认为是鞍点的两个定义。
- 价格或税解释

4.4 最优性条件
考虑一般问题,即不一定是凸问题。
互补松弛性:
设原问题和对偶问题的最优值都可以达到且相等 (即强对偶性成立)。令 $x^{\star}$ 是原问题的最优解, $\left(\lambda^{\star}, \nu^{\star}\right)$ 是对偶问题的最优解, 这表明
\[\begin{aligned} f_{0}\left(x^{\star}\right) &=g\left(\lambda^{\star}, \nu^{\star}\right) \\ &=\inf _{x}\left(f_{0}(x)+\sum_{i=1}^{m} \lambda_{i}^{\star} f_{i}(x)+\sum_{i=1}^{p} \nu_{i}^{\star} h_{i}(x)\right) \\ & \leqslant f_{0}\left(x^{\star}\right)+\sum_{i=1}^{m} \lambda_{i}^{\star} f_{i}\left(x^{\star}\right)+\sum_{i=1}^{p} \nu_{i}^{\star} h_{i}\left(x^{\star}\right) \\ & \leqslant f_{0}\left(x^{\star}\right) . \end{aligned}\]第一个等式说明最优对偶间隙为零, 第二个等式是对偶函数的定义。第三个不等式是根据 Lagrange 函数关于 $x$ 求下确界小于等于其在 $x=x^{\star}$ 处的值得来。最后一个不等式的成立是因为 $\lambda_{i}^{\star} \geqslant 0, f_{i}\left(x^{\star}\right) \leqslant 0, i=1, \cdots, m$, 以及 $h_{i}\left(x^{\star}\right)=0, i=1, \cdots, p$ 。因此,在上面的式子链中, 两个不等式取等号。
结论1: $L\left(x, \lambda^{\star}, \nu^{\star}\right)$ 关于 $x$ 求极小时在 $x^{\star}$ 处取得最小值。( Lagrange 函数 $L\left(x, \lambda^{\star}, \nu^{\star}\right)$ 也可以有其他最小点; $x^{\star}$ 只是其中一个最小点。)。因为 $L\left(x, \lambda^{\star}, \nu^{\star}\right)$ 关于 $x$ 求极小在 $x^{\star}$ 处取得最小值, 因此函数在 $x^{\star}$ 处的导数必须为零, 即,
\[\nabla f_{0}\left(x^{\star}\right)+\sum_{i=1}^{m} \lambda_{i}^{\star} \nabla f_{i}\left(x^{\star}\right)+\sum_{i=1}^{p} \nu_{i}^{\star} \nabla h_{i}\left(x^{\star}\right)=0\]该条件称为稳定性。
结论2: $\lambda_{i}^{\star} f_{i}\left(x^{\star}\right)=0, \quad i=1, \cdots, m$ 该条件称为互补松弛性;它对任意原问题最优解 $x^{\star}$ 以及对偶问题最优解 $\left(\lambda^{\star}, \nu^{\star}\right)$ 都成立(当强对偶性成立时)。粗略地讲, 上式意味着在最优点处, 除了第 $i$ 个约束起作用的情况, 最优 Lagrange 乘子($\lambda$)的第 $i$ 项都为零。
KKT最优性条件
假设函数 $f_{0}, \cdots, f_{m}, h_{1}, \cdots, h_{p}$ 可微(因此定义域是开集),但是并不假设这些函数是凸的。又满足 $d^{\star}=p^{\star}$ 的条件,即强对偶成立。
KKT条件:
令 $x^{\star}$ 和 $\left(\lambda^{\star}, \nu^{\star}\right)$ 分别是原问题和对偶问题的某对最优解, 对偶间隙为零。
\[\begin{aligned} f_{i}\left(x^{\star}\right) \leqslant 0, & \ i=1, \cdots, m \\ h_{i}\left(x^{\star}\right)=0, & \ i=1, \cdots, p \\ \lambda_{i}^{\star} \geqslant 0, & \ i=1, \cdots, m \\ \lambda_{i}^{\star} f_{i}\left(x^{\star}\right)=0, & \ i=1, \cdots, m \\ \nabla f_{0}\left(x^{\star}\right)+\sum_{i=1}^{m} \lambda_{i}^{\star} \nabla f_{i}\left(x^{\star}\right)+\sum_{i=1}^{p} \nu_{i}^{\star} \nabla h_{i}\left(x^{\star}\right)=0, & \end{aligned}\]上面五个式子构成KKT条件,前面两个称为原问题可行性(primal feasibility),第三个称为对偶可行性(dual feasibility),第四个称为互补松弛性(complementary slackness),第五个称为稳定性(stationarity),共四类。
在非凸问题下,KKT条件是必要条件,在凸问题下,KKT条件是充要条件,即满足KKT条件的($x,\lambda,\nu$)也是原、对偶最优解。
一个经典的利用KKT条件求解的凸优化问题
注水。考虑如下凸优化问题
\[\begin{array}{ll} \operatorname{minimize} & -\sum_{i=1}^{n} \log \left(\alpha_{i}+x_{i}\right) \\ \text { subject to } & x \succeq 0, \quad \mathbf{1}^{T} x=1, \end{array}\]其中 $\alpha_{i}>0$。上述问题源自信息论, 将功率分配给 $n$ 个信道。变量 $x_{i}$ 表示分配给第 $i$ 个信道的发射功率, $\log \left(\alpha_{i}+x_{i}\right)$ 是信道的通信能力或者通信速率, 因此上述问题即为将值为一的总功率分配给不同的信道, 使得总的通信速率最大。
对不等式约束 $x^{\star} \succeq 0$ 引入 Lagrange 乘子 $\lambda^{\star} \in \mathbf{R}^{n}$, 对等式约束 $\mathbf{1}^{T} x=1$ 引入一个乘子 $\nu^{\star} \in \mathbf{R}$, 我们得到如下 KKT 条件
\[\begin{array}{c} x^{\star} \succeq 0, \quad \mathbf{1}^{T} x^{\star}=1, \quad \lambda^{\star} \succeq 0, \quad \lambda_{i}^{\star} x_{i}^{\star}=0, \quad i=1, \cdots, n, \\ -1 /\left(\alpha_{i}+x_{i}^{\star}\right)-\lambda_{i}^{*}+\nu^{\star}=0, \quad i=1, \cdots, n . \end{array}\]注意,写Lagrange函数时,不等式函数需要小于等于0,如果大于等于0,就需要对不等式函数变号。
可以直接求解这些方程得到 $x^{\star}, \lambda^{\star}$, 以及 $\nu^{\star}$。注意到 $\lambda^{\star}$ 在最后一个方程里是一个松弛变量, 所以可以消去, 得到
\[\begin{array}{c} x^{\star} \succeq 0, \quad \mathbf{1}^{T} x^{\star}=1, \quad x_{i}^{\star}\left(\nu^{\star}-1 /\left(\alpha_{i}+x_{i}^{\star}\right)\right)=0, \quad i=1, \cdots, n, \\ \nu^{\star} \geqslant 1 /\left(\alpha_{i}+x_{i}^{\star}\right), \quad i=1, \cdots, n \end{array}\]如果 $\nu^{\star}<1 / \alpha_{i}$, 只有当 $x_{i}^{\star}>0$ 时最后一个条件才成立, 而由第三个条件可知 $\nu^{\star}=$ $1 /\left(\alpha_{i}+x_{i}^{*}\right)$ 。 求解 $x_{i}^{\star}$, 我们得出结论: 当 $\nu^{\star}<1 / \alpha_{i}$ 时, 有 $x_{i}^{\star}=1 / \nu^{\star}-\alpha_{i}$。如果 $\nu^{\star} \geqslant 1 / \alpha_{i}$, 那么 $x_{i}^{\star}>0$ 不会发生, 这时因为如果 $x_{i}^{\star}>0$, 那么 $\nu^{\star} \geqslant 1 / \alpha_{i}>1 /\left(\alpha_{i}+x_{i}^{\star}\right)$, 违背了互补松弛条件。因此, 如果 $\nu^{\star} \geqslant 1 / \alpha_{i}$, 那么 $x_{i}^{\star}=0$ 。所以有下式
\[x_{i}^{\star}=\left\{\begin{array}{ll} 1 / \nu^{\star}-\alpha_{i} & \nu^{\star}<1 / \alpha_{i} \\ 0 & \nu^{\star} \geqslant 1 / \alpha_{i} \end{array}\right.\]或者, 更简洁地, $x _ {i}^{\star}=\max \{0,1 / \nu^{\star} - \alpha _{i} \} _ {\circ}$ 将 $x _ {i}^{\star}$ 的表达式代入条件 $\mathbf{1}^{T} x^{\star}=1$ 我们得到
\[\sum_{i=1}^{n} \max \left\{0,1 / \nu^{\star}-\alpha_{i}\right\}=1\]方程左端是 $1 / \nu^{\star}$ 的分段线性增函数, 分割点为 $\alpha_{i}$, 因此上述方程有唯一确定的解。 上述解决问题的方法称为注水。这是因为, 我们可以将 $\alpha_{i}$ 看做第 $i$ 片区域的水平线, 然后对整个区域注水, 使其具有深度 $1 / \nu$, 如图 $5.7$ 所示。所需的总水量为 $\sum_{i=1}^n \max \{0,1 / \nu^{\star}-\alpha_{i}\}$ 。不断注水, 直至总水量为 1 。第 $i$ 个区域的水位深度即为最优 $x_{i}^{\star}$ 。
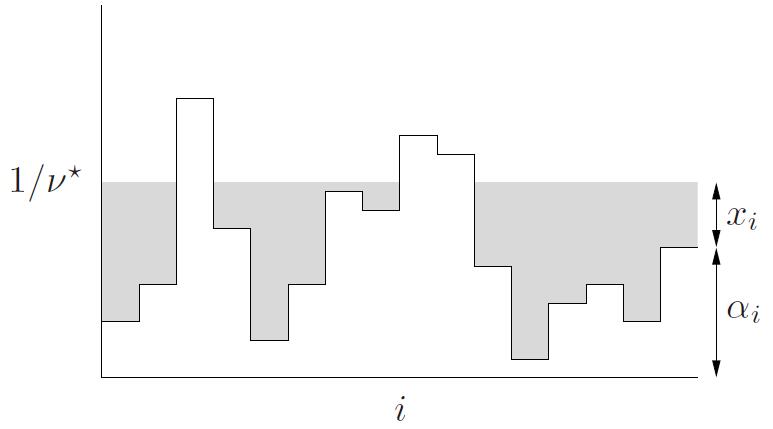
图5.7 注水算法的图示。每片区域的高度为 $\alpha_{i}$ 。总水量为 1, 对整个区域注水使其高度达到 $1 / \nu^{\star}$ 。每片区域上水的高度 (阴影部分所示) 即最优值 $x_{i}^{\star}$ 。
4.5 例子:
通过一些例子,说明对凸问题的等价变形可以得到不一样的对偶问题,并介绍三个等价变形的方法。
引入新的变量以及相应的等式约束
无约束问题
\[\text { minimize } f_{0}(A x+b)\]其 Lagrange 对偶问题没有意义。
将其等价变形为
\[\begin{array}{ll} \operatorname{minimize} & f_{0}(y) \\ \text { subject to } & A x+b=y \end{array}\]变换后的问题的Lagrange 函数是
\[L(x, y, \nu)=f_{0}(y)+\nu^{T}(A x+b-y)\]为了得到对偶函数, 关于 $x$ 和 $y$ 极小化 $L$ 。通过对 $x$ 极小化可以得到, 除非 $A^{T} \nu=0$, 否则 $g(\nu)=-\infty$。若 $A^{T} \nu=0$ 有
\[g(\nu)=b^{T} \nu+\inf _{y}\left(f_{0}(y)-\nu^{T} y\right)=b^{T} \nu-f_{0}^{*}(\nu)\]其中 $f_{0}^{*}$ 是 $f_{0}$ 的共轭函数。注意:$\operatorname{inf}_{x} (f(x))=-\operatorname{sup}_x (-f(x))$。那么对偶问题可以描述为
\[\begin{array}{ll} \operatorname{maximize} & b^{T} \nu-f_{0}^{*}(\nu) \\ \text { subject to } & A^{T} \nu=0 \end{array}\]变换目标函数
原问题:
\[\operatorname{minimize} \quad\|A x-b\| \text {, }\]变换目标函数:
\[\begin{array}{ll} \operatorname{minimize} & (1 / 2)\|y\|^{2} \\ \text { subject to } & A x-b=y \end{array}\]新问题的对偶问题为
\[\begin{array}{ll} \text { maximize } & -(1 / 2)\|\nu\|_{*}^{2}+b^{T} \nu \\ \text { subject to } & A^{T} \nu=0 \end{array}\]与原问题的对偶问题不一样。
隐式约束
接下来考虑一个简单的重新描述问题的方式, 通过修改目标函数将约束包含到目标函数中, 当约束被违背时, 目标函数为无穷大。
具有框约束的线性规划问题:
\[\begin{array}{ll} \operatorname{minimize} & c^{T} x \\ \text { subject to } & A x=b \\ & l \preceq x \preceq u \end{array}\]其中 $A \in \mathbf{R}^{p \times n}$ 且 $l \prec u$。约束 $l \preceq x \preceq u$ 有时称为框约束或者变量的界。
对偶问题:
\[\begin{array}{cl} \operatorname{maximize} & -b^{T} \nu-\lambda_{1}^{T} u+\lambda_{2}^{T} l \\ \text { subject to } & A^{T} \nu+\lambda_{1}-\lambda_{2}+c=0 \\ & \lambda_{1} \succeq 0, \quad \lambda_{2} \succeq 0 \end{array}\]其中,$\lambda_{1}$ 对应不等式约束 $x \preceq u$, 而 $\lambda_{2}$ 对应不等式约束 $l \preceq x$ 。
修改目标函数将约束包含到目标函数中,
\[\begin{array}{ll} \operatorname{minimize} & f_{0}(x) \\ \text { subject to } & A x=b \end{array}\]其中 $f_0 (x)$ 定义为
\[f_{0}(x)=\left\{\begin{array}{ll} c^{T} x & l \preceq x \preceq u \\ \infty & \text { 其他情况. } \end{array}\right.\]问题的对偶函数为
\[\begin{aligned} g(\nu) &=\inf _{l \preceq x \preceq u}\left(c^{T} x+\nu^{T}(A x-b)\right) \\ &=\inf _{l \preceq x \preceq u} \left( A^T \nu+c \right)^T x-\nu^T b\\ &=-b^{T} \nu+l^{T}\left(A^{T} \nu+c\right)^{+} -u^{T}\left(A^{T} \nu+c\right)^{-} \end{aligned}\]其中 $y_{i}^{+}=\max \{y_{i}, 0\}, y_{i}^{-}=\max \{-y_{i}, 0\}$ 。所以此时我们可以得到函数 $g$ 的解析表达式, 它是一个凹的分片线性函数。(当 $A^T \nu +c$ 正时,因为 $\inf$ ,所以 $x=l$,当 $A^T \nu +c$ 负时,取 $x=u$,因为 $y_{i}^{-}=\max \{-y_{i}, 0\}$ ,所以 $u^T$ 前面需要有个负号。)
4.6 敏感性分析
原问题:
\[\begin{array}{ll} \operatorname{minimize} & f_{0}(x) \\ \text { subject to } & f_{i}(x) \leqslant 0, \quad i=1, \cdots, m \\ & h_{i}(x)=0, \quad i=1, \cdots, p \end{array}\]干扰问题:
\[\begin{array}{ll} \operatorname{minimize} & f_{0}(x) \\ \text { subject to } & f_{i}(x) \leqslant u_i, \quad i=1, \cdots, m \\ & h_{i}(x)=w_i, \quad i=1, \cdots, p \end{array}\]干扰问题的最优值为 $p^{\star}(u,w)$,且 $p^{\star}(0,0)=p^{\star}$,$p^{\star}$ 是原问题的最优值。
性质一:若原问题为凸问题,则 $p^{\star}(u,w)$ 为 $(u,w)$ 的凸函数。
证明:
\[p^{\star}(u,w)=\inf _x \{ f_0(x) \mid f_i(x) \leq u_i,i=1,\cdots,m,h_i(x) \leq w_i,i=1,\cdots,p \}\]令
\[g(x,u,w) \triangleq f_0(x),\operatorname{dom} g=\operatorname{dom} f_0 \cap D\]其中 $D$ 表示
\[f_i(x) \leq u_i,i=1,\cdots,m,h_i(x) \leq w_i,i=1,\cdots,p\]关于 $(x,u,w)$ 的定义域。$\operatorname{dom} f_0$ 表示 $f_0$ 关于 $(x,u,w)$ 的定义域。
首先证明 $g(x,u,w)$ 关于 $(x,u,w)$ 是联合凸的,即证明函数是联合凸函数,且定义域是联合凸的。因为 $g(x,u,w)$ 是关于 $x$ 的函数,而原问题是凸问题,所以 $g$ 关于 $x$ 是凸的,又因为 $g$ 与 $u,w$ 无关,所以关于 $u,w$ 也是凸的,所以 $g(x,u,w)$ 关于 $(x,u,w)$ 是联合凸的。其次证明定义域是联合凸的。$\operatorname{dom} f_0(x,u,w)$ 是关于 $x$ 的凸集,因为原问题是凸函数。因为考虑 $f_0(x)$ 时与 $u,w$ 无关,所以
\[\operatorname{dom} f_0(x,u,w)=(\operatorname{dom} f_0(x),R^m,R^{p})\]此时考虑 $D$,$D$ 可以写为 $D_1 \cap D_2$。
其中,$D_1=\{(x,u) \mid f_i(x)-u_i \leq 0 \}$,因为 $f_i(x)$ 是关于 $x$ 的凸函数,所以也是关于 $(x,u)$ 的凸函数,$u_i$ 是关于 $u$ 的仿射函数,所以也是关于 $(x,u)$ 的凸函数,所以 $f_i(x)-u_i$ 一定是关于 $(x,u)$ 的凸函数,所以其下水平集 $D_1$ 是凸集,即 $f_i(x)-u_i \leq 0$ 是关于 $(x,u)$ 的凸集。同理,$D_2$ 是关于 $(x,w)$ 的凸集,所以 $D$ 一定是关于 $(x,u,w)$ 的凸集。所以证明了$g(x,u,w)$ 是关于 $(x,u,w)$ 的凸函数。
 因此,
因此,
是凸函数。
性质二:若原问题为凸,对偶间隙为零,$\lambda^{\star},v^{\star}$ 为原问题对偶最优解,则
\[p^\star(u,w) \geq p^{\star}(0,0)- {\lambda ^\star}^T u-{v^{\star}}^T w\]证明:

第二条性质的应用:
- 若 $\lambda _i ^{\star}$ 很大,且加紧第 $i$ 次不等式约束($u_i <0$)
- 若 $v_i ^{\star}$ 很大正值,使 $w_i <0$ 或 $v_i^{\star}$ 绝对值很大负值,使 $w_i >0$,则最优值增大
上述两条都是不利于最优值变小的,加紧不等式约束的时候需要特别注意。
性质三(局部敏感性):若原问题为凸,对偶间隙为零,且 $p^{\star}(u,w)$ 在 $(u,w)=(0,0)$ 处可微。
\[\lambda _i ^{\star} =-\frac{\partial{p^\star(0,0)}}{\partial{u_i}} \ \ \ v _i ^{\star} =-\frac{\partial{p^\star(0,0)}}{\partial{w_i}}\]将上式代入 $p^{\star}(u,w)$ 的泰勒展开式,就可以得到
\[p^{\star}(u,w) \simeq p^{\star}(0,0)-{\lambda^{\star}}^{T}u-{v^\star}^T w\]注意上面的约等于号是因为一阶泰勒展开缺少高阶项或者余项。粗略地说,在性质二的基础上,只要 $p^{\star}(u,w)$ 在 $(u,w)=(0,0)$ 处可微,性质二的不等式取到等号。
4.7 算法例子
LP松弛问题及求解
 Lagrange松弛之所以也叫做松弛是因为,Lagrange对偶问题给出的是原问题的下界,对偶间隙不等于0。之所以叫 Lagrange 是因为做了对偶,注意线性规划松弛只是做了松弛,没做对偶。
Lagrange松弛之所以也叫做松弛是因为,Lagrange对偶问题给出的是原问题的下界,对偶间隙不等于0。之所以叫 Lagrange 是因为做了对偶,注意线性规划松弛只是做了松弛,没做对偶。
 结论是:通过 Lagrange 松弛得到的下界和线性规划松弛得到的下界是一样的,也就是说,Lagrange 松弛和线性规划松弛互为对偶。
结论是:通过 Lagrange 松弛得到的下界和线性规划松弛得到的下界是一样的,也就是说,Lagrange 松弛和线性规划松弛互为对偶。
罚函数
 一般的做法是:先取一个较小的 $\alpha$ ,算出此时的 $x$,之后逐渐增大 $\alpha$,从上次找到的 $x$ 开始搜索此时的最优$x$,后面继续循环上述操作直到找到最优值。用超平面的思想解释:当 $\alpha$较小时,允许 $x^{\star}$ 取到远离超平面处,但是随着 $\alpha$ 增大时,$x^{\star}$ 和超平面的距离缩小,直到位于超平面上。
一般的做法是:先取一个较小的 $\alpha$ ,算出此时的 $x$,之后逐渐增大 $\alpha$,从上次找到的 $x$ 开始搜索此时的最优$x$,后面继续循环上述操作直到找到最优值。用超平面的思想解释:当 $\alpha$较小时,允许 $x^{\star}$ 取到远离超平面处,但是随着 $\alpha$ 增大时,$x^{\star}$ 和超平面的距离缩小,直到位于超平面上。
下面证明罚函数得到的最优值小于等于原问题的最优值:
\[\tilde{x}=\operatorname{argmin} _x \ f_0(x)+\frac{\alpha}{2} \Vert Ax-b \Vert _2^2\]其中,$\tilde{x}$ 表示罚函数的最优点。其一阶导数为:
\[\nabla f_0(\tilde{x})+\alpha A^T(A\tilde{x}-b)=0\]另一个函数求一阶导数也同样可以得到上式,因此具有相同的最优点:
\[\tilde{x}=\operatorname{argmin} _x \ f_0(x)+\alpha (A\tilde{x}-b)^T(Ax-b)\]若记 $v=\alpha (A \tilde{x}-b)$,实际上 $f_0(x)+v^T(Ax-b)$ 就是原问题的 Lagrange 函数,其对偶函数为
\[\begin{aligned} g(\alpha(A \tilde{x}-b)) &= \inf _x \{ f_0(x)+\alpha(A \tilde{x}-b)^T(Ax-b) \} \\ &= f_0(\tilde{x})+\alpha \Vert A \tilde{x}-b \Vert _2^2 \end{aligned}\]由于原问题是凸问题,弱Slater条件成立,强对偶性成立。所以
\[p^{\star}=d^{\star} \geq g(\alpha(A \tilde{x}-b)) = f_0(\tilde{x})+\alpha \Vert A \tilde{x}-b \Vert _2 ^2 > f_0(\tilde{x})\]所以原问题的最优值 $p^{\star}$ 大于等于通过罚函数的方法得到的 $f_0(x)$ 的最优值 $f_0(\tilde{x})$。
其实,上面的证明过程说明:每次去求罚函数的最优解,就是在求原问题的对偶函数的最优解,所以罚函数方法给出的是原问题的下界。

对数障碍法(log-barrier)
带线性不等式约束的可微凸优化问题:
\[\begin{array}{ll} \operatorname{min} & f_0(x)\\ \text{s.t.} & Ax \geq b \ x \in R^n ,A \in R^{m \times n} , b \in R^{m} \end{array}\]log-barrier:
\[\text{min} \ f_0(x)-\sum_{i=0}^m u \text{log}(a_i^T x-b_i)\]log-barrier 属于内点法中的一个,顾名思义,log-barrier 法必须让初始迭代点从约束集内部开始,靠近边界就会被“推向”内部,这与罚函数的本质还是不一样的。
5 无约束优化问题
5.1 无约束优化问题
特殊情况下,可以通过解析求解最优性方程 $(9.2)$ 确定无约束凸优化问题的解:
\[\nabla f\left(x^{\star}\right)=0 \tag{9.2}\]但是一般情况下,必须采用迭代算法求解方程 $(9.2)$。
本章介绍的方法需要一个适当的初始点 $x^{(0)}$, 该初始点必须属于 $\operatorname{dom} f$, 并且下水平集
\[S=\left\{x \in \operatorname{dom} f \mid f(x) \leqslant f\left(x^{(0)}\right)\right\}\]必须是闭集。
5.2 下降方法
强凸性
若存在 $m>0$ 使得
\[\nabla^{2} f(x) \succeq m I\]对任意的 $x \in S$ 都成立,我们称 $f(x)$ 具有强凸性。
强凸性的性质
\[f(y) \geqslant f(x)+\nabla f(x)^{T}(y-x)+\frac{m}{2}\|y-x\|_{2}^{2}\]对 $S$ 中任意的 $x$ 和 $y$ 都成立。
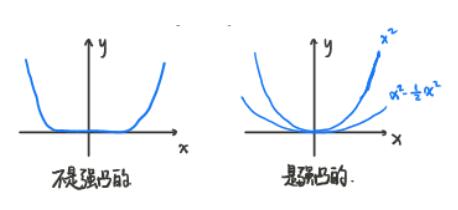
关于 $\nabla^{2} f(x)$ 的上界
\[\nabla^{2} f(x) \preceq M I\]对所有 $x \in S$ 都成立。关于 Hessian 矩阵的这个上界意味着对任意的 $x, y \in S$,
\[f(y) \leqslant f(x)+\nabla f(x)^{T}(y-x)+\frac{M}{2}\|y-x\|_{2}^{2}\]误差上下界
当 $\nabla f(x) \rightarrow 0$ 时, $f(x) \rightarrow f\left(x^{*}\right) ?$
假设 $f(x)$ 时二次可微且具有强凸性:
\[\forall x, y \in \text { domf } f(y) \geqslant f(x)+\nabla f^{T}(x)(y-x)+\frac{1}{2} m\|y-x\|_{2}^{2}\]$x$ 给定,
\[f(x)+\nabla f^{T}(x)(y-x)+\frac{1}{2} m\|y-x\|_{2}^{2}\]是 $y$ 的凸函数。
使关于 $y$ 的一阶导等于0的 $y$ 是最优解。
\[\nabla f^{T}(x)+m(\tilde{y}-x)=0 \quad \tilde{y}=x-\frac{\nabla f^{T}(x)}{m}\]所以
\[f(y) \geqslant f(x)+\nabla f^{T}(x)(y-x)+\frac{1}{2} m\|y-x\|_{2}^{2} \geq f(x)-\frac{1}{2 m}\|\nabla f(x)\|_{2}^{2}\]因为 $p^{\star}$ 是 $f(y)$ 的最小值,也满足上述不等式,所以
\[p^{*} \geq f(x)-\frac{1}{2 m}\|\nabla f(x)\|_{2}^{2} \tag{9.9}\]且
\[p^{*}+\frac{1}{2 m}\|\nabla f(x)\|_{2}^{2} \geqslant f(x) \geqslant p^{*}\]可以得出一个关于误差的上界
\[\left\|f(x)-p^{*}\right\|_{2} \leqslant \frac{1}{2 m}\|\nabla f(x)\|_{2}^{2}\]当 $\nabla f(x) \rightarrow 0$ 时,$x \rightarrow x^{*}$ ?
根据柯西施瓦兹不等式
\[|\langle x, y\rangle| \leq\|x\|\|y\|\]一定有
\[\langle a, b\rangle+\|a||\| b \| \geqslant 0\]所以
\[\begin{aligned} f(x) \geqslant p^{*}=f\left(x^{*}\right) & \geqslant f(x)+\nabla f^{T}(x)\left(x^{*}-x\right)+\frac{m}{2}\left\|x^{*}-x\right\|_{2}^{2} \\ & \geqslant f(x)-\|\nabla f(x)\|_{2}\left\|x^{*}-x\right\|_{2}+\frac{m}{2}\left\|x^{*}-x\right\|_{2}^{2} . \end{aligned}\] \[f(x) \geqslant p^{*} \Rightarrow-\|\nabla f(x)\|_{2}\left\|x^{*}-x\right\|_{2}+\frac{m}{2}\left\|x^{*}-x\right\|_{2} ^2 \leq 0\]所以
\[\left\|x^{*}-x\right\|_{2} \leqslant \frac{2}{m}\|\nabla f(x)\|_{2}\] \[\exists M>0, \forall x \in \operatorname{dom} f, \nabla^{2} f(x) \preceq M I\]同样可以得出一个关于误差的不等式
\[p^{\star} \leqslant f(x)-\frac{1}{2 M}\|\nabla f(x)\|_{2}^{2} \tag{9.14}\]与 $(9.9)$ 对应。
迭代
\[x^{(k+1)}=x^{(k)}+t^{(k)} \Delta x^{(k)}\]其中,$t^{(k)}>0$,$\Delta x$ 称为搜索方向或者步径(不需要具有单位范数),$t^{(k)}$ 称为第k次迭代的步长。
为保证每次迭代都是下降的,搜索方向必须满足
\[\nabla f\left(x^{(k)}\right)^{T} \Delta x^{(k)}<0\]即搜索方向和负梯度的夹角必须是锐角。
通用下降方法:
给定 初始点 $x \in \operatorname{dom} f$。
重复进行
$\;\;\;\;$ 1. 确定下降方向 $\Delta x$
$\;\;\;\;$ 2. 直线搜索。选择步长 $t>0$ 。
$\;\;\;\;$ 3. 俢改。 $x:=x+t \Delta x$
直到 满足停止准则。
停止准则:一般 $|\nabla f(x)|_{2} \leqslant \eta$。
回溯直线搜索算法

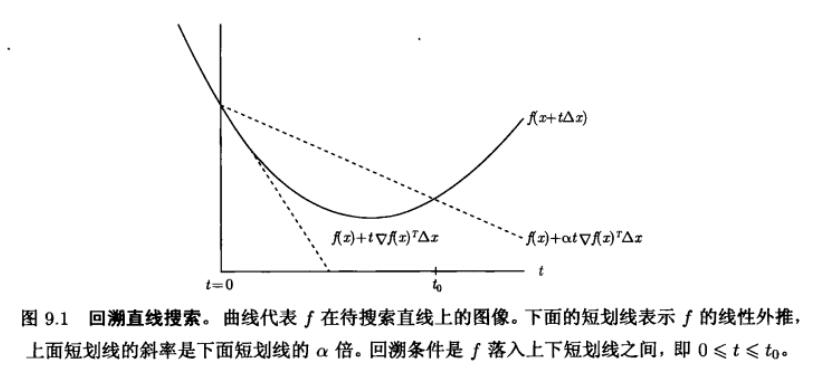 在实际计算中, 我们首先用 $\beta$ 乘 $t$ 直到 $x+t \Delta x \in \operatorname{dom} f $; 然后才开始检验不等式 $f(x+t \Delta x) \leqslant f(x)+\alpha t \nabla f(x)^{T} \Delta x$ 是否成立。
在实际计算中, 我们首先用 $\beta$ 乘 $t$ 直到 $x+t \Delta x \in \operatorname{dom} f $; 然后才开始检验不等式 $f(x+t \Delta x) \leqslant f(x)+\alpha t \nabla f(x)^{T} \Delta x$ 是否成立。
梯度下降

梯度下降算法收 敛性分析
以下笔记图片来源于 CSDN博主——及时行樂_:
精确线搜索
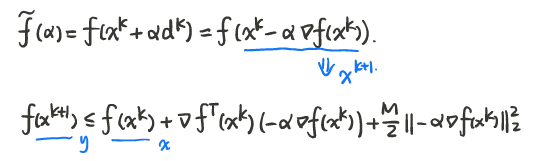
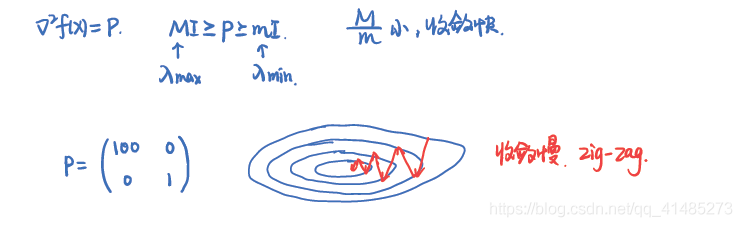
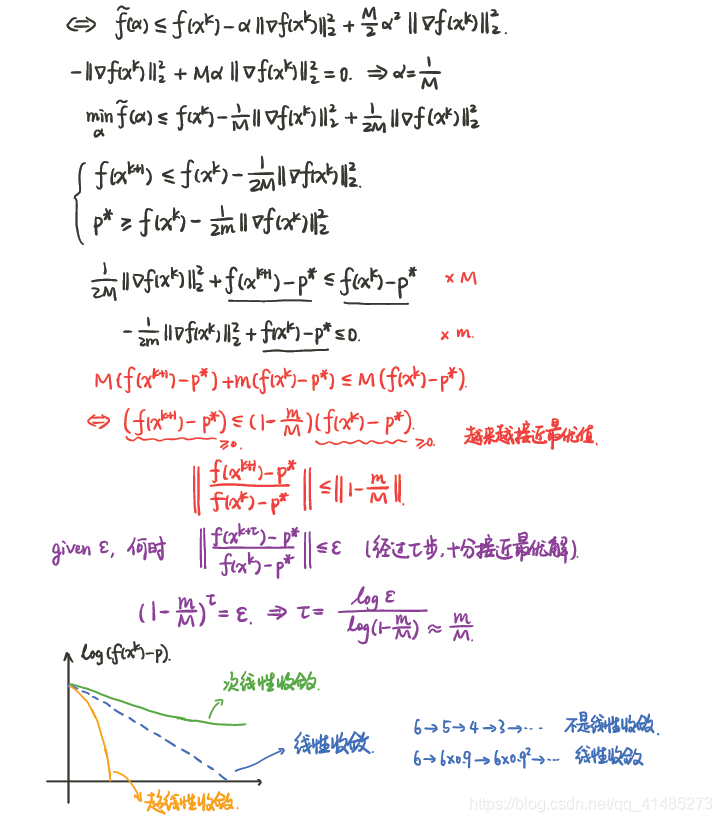 因此所需迭代次数的上界将随着 $M / m$ 增大而近似线性的增长。$M/m$ 称为条件数。当 $x^{\star}$ 附近 $f$ 的 Hessian 矩阵具有较小的条件数,收敛较快。
因此所需迭代次数的上界将随着 $M / m$ 增大而近似线性的增长。$M/m$ 称为条件数。当 $x^{\star}$ 附近 $f$ 的 Hessian 矩阵具有较小的条件数,收敛较快。
非精确线搜索(回溯直线搜索)
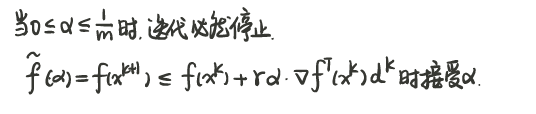
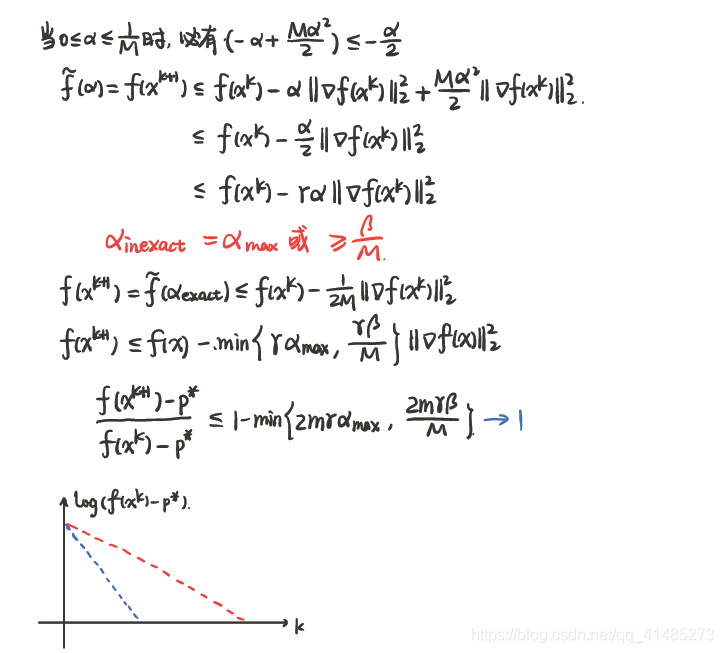 $\alpha _{max}$ 表示第一次就被满足的步长,即最大步长(因为每次迭代乘以小于1的系数从而减小步长)。
例子说明:
$\alpha _{max}$ 表示第一次就被满足的步长,即最大步长(因为每次迭代乘以小于1的系数从而减小步长)。
例子说明:
最速下降法
对 $f(x+v)$ 在 $x$ 处进行一阶 Taylor 展开,
\[f(x+v) \approx \widehat{f}(x+v)=f(x)+\nabla f(x)^{T} v\]其中右边第二项 $\nabla f(x)^{T} v$ 是 $f$ 在 $x$ 处沿方向 $v$ 的方向导数。它近似给出了 $f$ 沿小的 步径 $v$ 会发生的变化。如果其方向导数是负数, 步径 $v$ 就是下降方向。
令 $|\cdot|$ 为 $\mathbf{R}^{n}$ 上的任意范数。我们定义一个规范化的最速下降方向如下:
\[\Delta x_{\mathrm{nsd}}=\operatorname{argmin}\left\{\nabla f(x)^{T} v \mid\|v\|=1\right\} .\]
采用 Euclid 范数
采用 Euclid 范数的最速下降方向就是负梯度方向。
采用 $\ell_{1}$-范数
令 $i$ 是满足下式的任意下标,$ \Vert \nabla f(x) \Vert_{\infty} =$ $\lvert (\nabla f(x)) _i \lvert $。
于是,$\ell_{1}$-范数下的一个规范化的最速下降方向 $\Delta x_{\mathrm{nsd}}$ 由下式给出,
\[\Delta x_{\mathrm{nsd}}=-\operatorname{sign}\left(\frac{\partial f(x)}{\partial x_{i}}\right) e_{i}\]其中 $e_{i}$ 表示第 $i$ 个标准基向量。
通俗地说,就是每次迭代我们选择 $\nabla f(x)$ 的绝对值最大的分量,然后取和 $(\nabla f(x))_{i}$ 相反的符号的第 $i$ 个标准基向量。
采用 $\ell_{\infty}$-范数
\[\Delta x_{\mathrm{nsd}}=\sum_{i=1}^{n} \left(-\operatorname{sign}\left(\frac{\partial f(x)}{\partial x_{i}}\right) e_{i}\right)\]下面是上述三种最速下降法的图例:

最速下降法的变种
1. 坐标轮换法
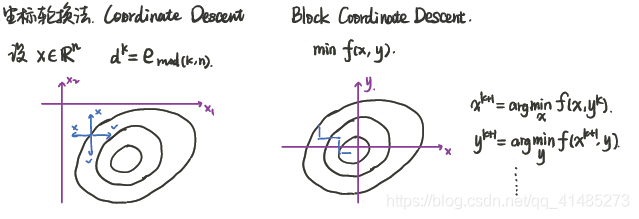 上述左图。原来的最速下降法需要计算出迭代点的梯度,根据梯度分量的大小和方向确定使得 $\nabla f(x)^{T} v$ 最小的 $v$。自然而然地,我们就会想到,如果不计算梯度,按照顺序依次选取各 $v$,可以减小计算量。为了保证收敛,需要对步长进行调整,之前是令 $t>0$,在这里由于轮换的 $v$ 无法保证目标函数往减小的方向走,就需要选取合适的 $t$,来保证下降,显然此时的 $t$ 应该是能取到负数的。
上述左图。原来的最速下降法需要计算出迭代点的梯度,根据梯度分量的大小和方向确定使得 $\nabla f(x)^{T} v$ 最小的 $v$。自然而然地,我们就会想到,如果不计算梯度,按照顺序依次选取各 $v$,可以减小计算量。为了保证收敛,需要对步长进行调整,之前是令 $t>0$,在这里由于轮换的 $v$ 无法保证目标函数往减小的方向走,就需要选取合适的 $t$,来保证下降,显然此时的 $t$ 应该是能取到负数的。

2. 分块坐标轮换法
上述右图。该方法针对多个变量的目标函数。其思想是,对于二变量函数,假设开始时 $x$ 处于 $(x^0,y^0)$ 处,此时固定 $y=y^0$,寻找使得 $f(x,y^0)$ 最小的 $x$,即为 $x^1$,接下来,固定 $x=x^1$,寻找使得 $f(x^1,y)$ 最小的 $y$,记为 $y^2$,不断迭代直至找到最优点。
3. 若 $f(x)$ 在某些点不可微
使用次梯度代替梯度,知乎-次梯度方法:
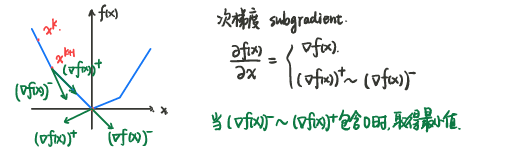
牛顿法
对于最速下降法,其将 $x^k$ 处的一阶泰勒展开作为目标函数,找出在 $\Vert v \Vert \leq 1$ 约束下使得目标函数 $f(x^k)+\nabla f(x)^T v$ 最小的方向 $v$,也就是找出使得 $\nabla f(x)^T v$ 最小的方向 $v$。
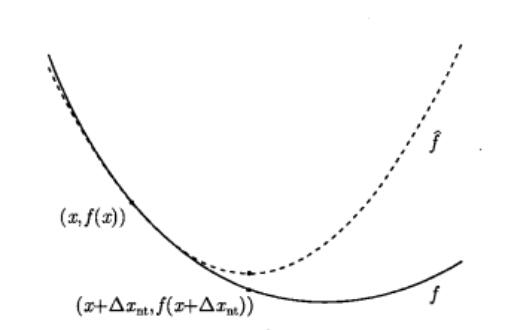
牛顿法的思想和最速下降法是相似的,牛顿法将 $x^k$ 处的目标函数近似为二阶泰勒展开,通过寻找使得
\[\widehat{f}(x^k+v)=f(x^k)+\nabla f(x^k)^{T} v+\frac{1}{2} v^{T} \nabla^{2} f(x^k) v\]最小的 $v$,来确定 $x^k$ 处的最优方向。因为二阶泰勒有最低点,因此不需要对其进行约束就能找到最优的方向。
\[v^k=\operatorname{argmin} _v \{ f(x^k)+\nabla {f(x^k)}^T v+\frac{1}{2} v^T \nabla^{2} f(x^k) v \}\]通过对 $v$ 求一阶导,得到
\[v=-\nabla^{2} f(x)^{-1} \nabla f(x)\]即为牛顿方向。下图说明了这一过程。
最优点的判断
- 通过之前的两次迭代间目标函数的差值的范数小于给定值来判断。
- 通过二阶泰勒展开式的一次项等于 0 来判断。当目标接近最低点时,值的主要部分集中在零次项,一次项应该接近于 0。所以当
时,迭代停止,目标函数到达最低点。
牛顿法算法

收敛性分析
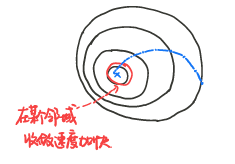
存在 $\eta>0$:
- 若 $|\nabla f(x)|_{2} \geq \eta:$ 阻尼牛顿阶段 (damped Newton phase)
- 若 $|\nabla f(x)|_{2}<\eta:$ 二次收敛阶段 (quadratically convergent phase)
在阻尼牛顿阶段,收敛速度慢,二次收敛阶段收敛速度快。粗略的说,一开始收敛慢,接近最优点时收敛速度快。
拟牛顿法
因为牛顿法需要计算 Hessian 矩阵和逆,有时候是非常不方便的,因此设计一个矩阵来代替 Hessian 矩阵,这就是拟牛顿法。BFGS法是一个常见方法。
无约束优化问题及算法汇总
\[\begin{array}{l} \min f(x): \\ \text { gradient descent } d^{k}=-\nabla f\left(x^{k}\right) \\ \text { steepest descent } d^{k}=\underset{\|v\|=1}{\arg \min }\left\{\nabla f^{T}\left(x^{k}\right) v\right\}\\ \text { coordinate descent }\\ \text { subgradient descent } d^{k}=-\frac{\partial f\left(x^{k}\right)}{\partial x}\\ \text { Newton's Method } d^{k}=\arg \min \left\{\nabla f^{T}(x) v+\frac{1}{2} v^{T} \nabla^{2} f(x) v\right\}=-\left(\nabla^{2} f\left(x^{k}\right)\right)^{-1} \nabla f\left(x^{k}\right) \\ \text { Quasi }-\text { Newten Method } d^{k}=-B^{-1} \nabla f\left(x^{k}\right) \end{array}\]5.3 有约束优化问题
本章讨论下述等式约束凸优化问题的求解方法,
\[\begin{array}{ll} \text { minimize } & f(x) \\ \text { subject to } & A x=b \end{array}\]其中 $f: \mathbf{R}^{n} \rightarrow \mathbf{R}$ 是二次连续可微凸函数, $A \in \mathbf{R}^{p \times n}$, rank $A=p<n$ 。 对 $A$ 的假设意味着等式约束数少于变量数, 并且等式约束互相独立。我们假定存在一个最优解 $x^{\star}$, 并用 $p^{\star}$ 表示其最优值, $p^{\star}=\inf {f(x) \mid A x=b}=f\left(x^{\star}\right)$ 。
可以通过求解 KKT 条件来解决:
\[A x^{\star}=b, \quad \nabla f\left(x^{\star}\right)+A^{T} \nu^{\star}=0\]但是很少情况可以直接解析求解。求解的方法主要有:
- 消除等式约束转化为等价的无约束问题求解。
- 如果是二次凸规划问题可以直接利用 KKT 条件解。
- 如果是一般的非线性规划将目标函数近似为二阶泰勒展开,然后对新的二次规划问题利用 KKT 条件求解。
二次凸规划问题
\[\begin{array}{c} \min \frac{1}{2} X^{T} P X+q^{T} X+r P \in S_{+}^{n} \\ \text { s.t. } A x=b \end{array}\]KKT条件:
\[\begin{array}{c} A x^{*}=b \\ P X^{*}+q+A^{T} v^{*}=0 \\ \Leftrightarrow\left[\begin{array}{cc} P & A^{T} \\ A & O \end{array}\right]\left[\begin{array}{l} x^{*} \\ v^{*} \end{array}\right]=\left[\begin{array}{c} -q \\ b \end{array}\right] \end{array}\]上述不等式可以通过高斯消元法、高斯赛德尔、雅可比法等求解。
一般非线性规划问题
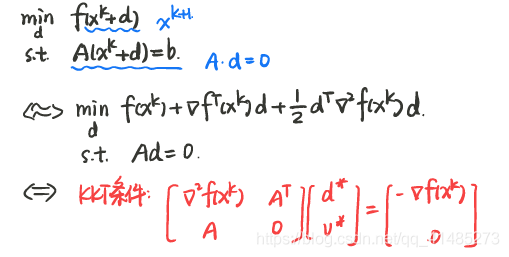 其中,$x^k$ 是可行的初始点,即满足 $A x^k=b$,所以有 $Ad=0$。目标函数换成其在 $x^k$ 附近的二阶 Taylor 近似。
其中,$x^k$ 是可行的初始点,即满足 $A x^k=b$,所以有 $Ad=0$。目标函数换成其在 $x^k$ 附近的二阶 Taylor 近似。
上式是凸函数。因此这是一个凸的带等式约束的二次极小问题。可以通过 KKT 条件求解。
求得牛顿方向 $d$ 后,
\[x^{k+1}=x^k+\alpha ^k d^k\]其中,步长 $\alpha$ 可以通过回溯直线或者精确搜索得到。显然,即使加入了 $\alpha$,$x^{k+1}$ 仍是可行解。
等式约束的牛顿算法
上述一般非线性规划问题的求解过程可以概括为:

拉格朗日法
拉格朗日法通过下述式子不断迭代求得最终解:
\[\begin{array}{c}\tag{10.1} x^{k+1}=x^{k}-\alpha^{k}\left(\nabla f\left(x^{k}\right)+A^{T} v^{k}\right) \\ v^{k+1}=v^{k}+\alpha^{k}\left(A x^{k}-b\right) \end{array}\]为保证对非凸问题仍可以求解,一般选取的步长 $\alpha$ 是一个递增序列,但是设置上界。
该方法有两种理解方式:
- 通过鞍点解释。
- 从惩罚函数解KKT条件来解释。
鞍点角度解释
回顾鞍点定理:如果 $x^{\star}$ 和 $\lambda^{\star}$ 分别是原问题和对偶问题的最优点, 且强对偶性成立, 则它们是 Lagrange 函数的一个鞍点。反过来同样成立: 如果 ( $x, \lambda$ ) 是 Lagrange 函数的一个鞍点, 那么 $x$ 是原问题的最优解, $\lambda$ 是对偶问题的最优解, 且最优对偶间隙为零。
\[L(x,v)=f(x)+v^T(Ax-b)\]满足下面条件的显然是鞍点:
\[(x^{\star},v^{\star})=\arg \underset{v}{ \max } \underset{x}{\min} L(x,v)\\ (x^{\star},v^{\star})=\arg \underset{x}{ \min } \underset{v}{\max} L(x,v)\]且对于鞍点来说,
\[\begin{array}{l} x^{\star}=\arg \underset{x}{ \min } L\left(x, v^{*}\right) \\ v^{\star}=\arg \underset{v}{ \max } L\left(x^{*}, v\right) \end{array}\]我们用梯度下降法来优化拉格朗日函数。首先来求 $x^{\star}$,$L(x,v^{\star})$ 的负梯度是 $-\nabla f\left(x^{k}\right)-A^{T} v^{\star}$
所以
\[x^{k+1}=x^{k}+\alpha^{k}\left(-\nabla f\left(x^{k}\right)-A^{T} v^{*}\right)\]由于 $v^{\star}$ 实际上未知,所以用 $v^{k}$ 近似替代。
由此我们得到了 $(10.1)$ 的式一。
同理,可以求出 $v^{\star}$。$L(x^{\star},v)$ 对 $v$ 求偏导,得到正梯度为 $-A x^{\star}+b$,所以
\[v^{k+1}=v^{k}+\alpha^{k}\left(A x^{\star}-b\right)\]用 $x^k$ 代替未知的 $x^{\star}$ 即得到 $(10.1)$ 的式二。
从惩罚函数解KKT条件来解释
原始问题的 KKT 条件:
\[\begin{align} A x^{\star} & =b \\ \nabla f\left(x^{\star}\right)+A^{T} v^{\star} & =0 \end{align}\]为了求解 KKT 条件,将其转化为无约束优化问题:
\[\min P(x, v)=\frac{1}{2}\|A x-b\|_{2}^{2}+\frac{1}{2}\left\|\nabla f(x)+A^{T} v\right\|_{2}^{2}\]只要 KKT 条件有解,就一定是无约束优化问题的解。
对于上述无约束优化问题,只要其搜索方向和负梯度方向夹角是锐角,就一定能保证下降,因此,
负梯度方向:
\[-\left.\nabla P(x, v)\right|_{\left(x^{k}, v^{k}\right)}=-\left(\begin{array}{c} A^{T}\left(A x^{k}-b\right)+\nabla^{2} f\left(x^{k}\right)\left(\nabla f\left(x^{k}\right)+A^{T} x^{k}\right) \\ A\left(\nabla f\left(x^{k}\right)\right)+A^{T} v^{k} \end{array}\right)\]拉格朗日法方向:
\[d^{k}=\left(\begin{array}{c} -\left(f\left(x^{k}\right)+A^{T} v^{k}\right) \\ A x^{k}-b \end{array}\right)\]两者做内积后
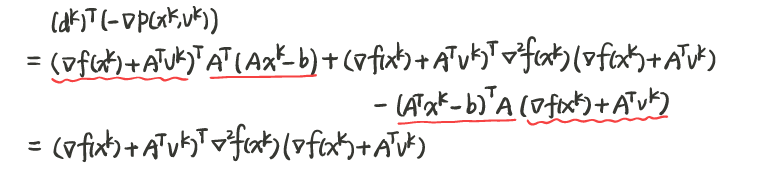
对于上述式子,当满足下述条件时,内积大于 0
\[\begin{align} \nabla f\left(x^{k}\right)+A^{T} v^{k} & \neq 0 \\ \nabla^{2} f\left(x^{k}\right) & \succ 0 \end{align}\]显然在非最优解处,上述约束成立,在最优解处已经不需要再搜索。所以拉格朗日方向确实可以找到带等式约束优化问题的最小值。
增广拉格朗日法
实际上拉格朗日法并非十分有用,收敛速度比较慢,且最优值不稳定。一般广泛使用的是增广拉格朗日方法,其收敛性和鲁棒性较好:
拉格朗日法是通过求拉格朗日函数的最优解来求解的,对于增广拉格朗日法,拉格朗日函数替换为增广拉格朗日函数
\[L_{c}(x, v)=f(x)+v^{T}(A x-b)+\frac{c}{2}\|A x-b\|_{2}^{2}\]显然这个 Lagrange 函数的原问题是
\[\begin{array}{lc} \min & f(x)+\frac{c}{2}\|A x-b\|_{2}^{2} \\ \text { s.t. } & A x=b \end{array}\]容易看出,上述问题和原问题
\[\begin{array}{lc} \min & f(x) \\ \text { s.t. } & A x=b \end{array}\]等价。
\[\left\{\begin{matrix} \min & f(x) \\ \text{s.t.} & Ax=b \end{matrix}\right. \underset{v^{\star}}{\overset{x^{\star}}{\Longleftrightarrow}} \left\{\begin{matrix} \min & f(x)+\frac{c}{2}\|A x-b\|_{2}^{2} \\ \\ \text{s.t.} & Ax=b \end{matrix}\right.\]上述等式意思是,两个问题不仅等价,其对偶问题也是等价的。
可以证明如下:

$c$ 通常为常数,如 1 ,绝大部分情况下都能收敛; 或者 $c$ 取递增的序列,也可保证大多数情况收敛。上述算法实际上是两步有序进行的(不同于 $(10.1)$ 的拉格朗日算法的 primal/dual 同时计算),将第一步结果代入第二步,其实增广拉格朗日法可以理解为计算对偶问题最优解 $v^{\star}$ 的算法。实际上,第一步并不需要十分精确的解,最终也能收敛。
性质:
- 若 $v=v^{\star}$, 则
- 若 $c \rightarrow+\infty$, 则
例子:
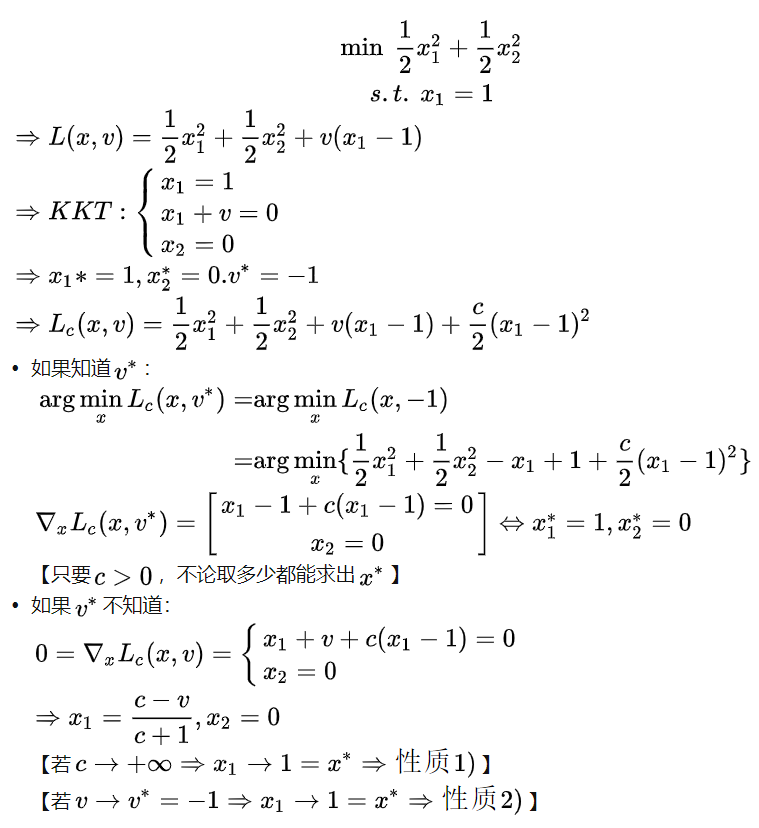
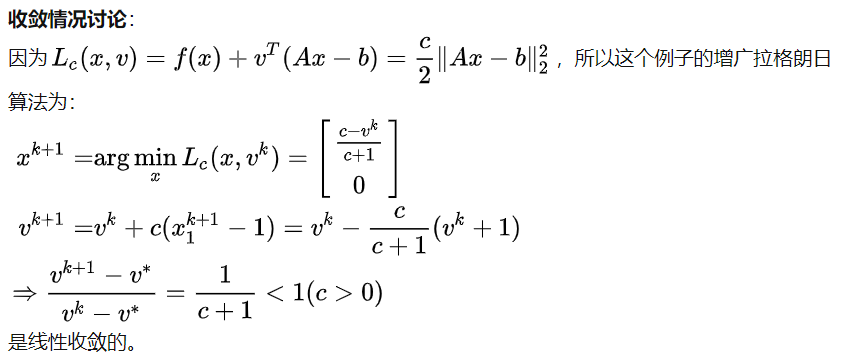 另一个例子:
另一个例子:
对于
\[\min _{x} f(x)+g(x) \tag{P}\]有时候单独的 $f$ 和 $g$ 都好优化,但是加起来就不好优化了。
上述无约束优化问题可以等价为
\[\begin{array}{lc}\tag{P1} \underset{x, z}{\min} & f(x)+g(z) \\ \text{s.t} & x=z \end{array}\]$(P1)$ 的增广拉格朗日函数为:
\[L_{c}(x, z, v)=f(x)+g(z)+v^{T}(x-z)+\frac{c}{2}\|x-z\|_{2}^{2}\]拉格朗日算法为:
\[\begin{align} \left\{x^{k+1}, z^{k+1}\right\} & =\arg \min _{x, z}\left\{f(x)+g(z)+v^{T}(x-z)+\frac{c}{2}\|x-z\|_{2}^{2}\right\} \\ v^{k+1} & =v^{k}+c\left(x^{k+1}-z^{k+1}\right) \end{align}\]第一个式子显然可以用分块坐标轮换法求解,不过显而易见的,分块坐标轮换求 $x^{\star},z^{\star}$ 的过程其实是一个循环,同时增广拉格朗日算法也是一个循环,因此此时两层循环计算量很大。所以引入交替方向乘子法(ADMM)。
交替方向乘子法(ADMM-Alternating Direction Method of Multipliers)
继续上述问题,ADMM算法告诉我们,可以先对 $x$ 单独求解,再单独对 $z$ 求解:
\[\begin{aligned} x^{k+1} &=\arg \min _{x} L_{c}\left(x, z^{k}, v^{k}\right) \\ z^{k+1} &=\arg \min _{z} L_{c}\left(x^{k+1}, z, v^{k}\right) \\ v^{k+1} &=v^{k}+c\left(x^{k+1}-z^{k+1}\right) \end{aligned}\]整理后等价于
\[\begin{aligned} x^{k+1} &=\arg \min _{x}\left\{f(x)+\frac{c}{2}\left\|x-z^{k}+\frac{v^{k}}{c}\right\|_{2}^{2}\right\} \\ z^{k+1} &=\arg \min _{z}\left\{g(z)+\frac{c}{2}\left\|z-x^{k+1}-\frac{v^{k}}{c}\right\|_{2}^{2}\right\} \\ v^{k+1} &=v^{k}+c\left(x^{k+1}-z^{k+1}\right) \end{aligned}\]ADMM 算法相当于是增广拉格朗日算法的改进,将两层循环减少到一层,减少了计算量。同时,ADMM算法适用于单独对某个变量进行求解是比较好优化的问题。
再看一个分布式计算用到 ADMM 的例子:
原问题:
\[\min _{x} \sum_{i=1}^{n} f_{i}(x)\]转换后等价于下述问题:
\[\begin{aligned} &\min _{x} \sum_{i=1}^{n} f_{i}\left(x_{i}\right) \\ &s . t . x_{i}=z, i=1, \ldots, n \end{aligned}\]增广拉格朗日函数:
\[L_{c}=\sum_{i=1}^{n} f_{i}\left(x_{i}\right)+\sum_{i=1}^{n} v_{i}^{T}\left(x_{i}-z\right)+\frac{c}{2} \sum_{i=1}^{n}\left\|x_{i}-z\right\|_{2}^{2}\]ADMM 方法:
- 第一步,
即
\[x_{i}^{k+1}=\arg \min _{x_{i}} f_{i}\left(x_{i}\right)+\frac{c}{2}\left\|x_{i}-z^{k}+\frac{v_{i}^{k}}{c}\right\|_{2}^{2}, \forall i\]- 第二步,
即
\[z^{k+1}=\frac{1}{n} \sum_{i=1}^{n}\left(x_{i}^{k+1}+\frac{v_{i}^{k}}{c}\right)\]- 第三步,
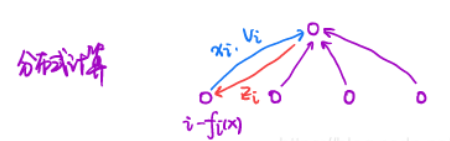
该例子采用 ADMM 算法,将一个原本集中才能解决的问题,分布式解决了。第 $i$ 号分机将 $x_{i}^{k+1},v_{i}^{k}$ 传给中央CPU,中央CPU计算出 $z_{i}^{k+1}$ 回传给第 $i$ 号分机,第 $i$ 号分机再计算出 $x_i ^{k+2},v _{i} ^{k+1}$ 准备传给中央CPU,完成一轮循环。本来完全依靠中央CPU大量算力的问题,通过分布式计算,将大部分工作量交给分布式CPU,中央CPU仅处理部分数据即可。
范数知识
向量内积,Euclid范数和夹角
向量内积:
\[\langle x, y\rangle=x^{T} y=\sum_{i=1}^{n} x_{i} y_{i}\]Euclid 范数, 或者 $\ell_{2}$-范数
\[\|x\|_{2}=\left(x^{T} x\right)^{1 / 2}=\left(x_{1}^{2}+\cdots+x_{n}^{2}\right)^{1 / 2}\]Cauchy-Schwartz 不等式
\[\left|x^{T} y\right| \leqslant\|x\|_{2}\|y\|_{2}\]两向量夹角:
\[\angle(x, y)=\arccos \left(\frac{x^{T} y}{\|x\|_{2}\|y\|_{2}}\right)\]矩阵内积,Frobenius范数
矩阵内积
\[\langle X, Y\rangle=\operatorname{tr}\left(X^{T} Y\right)=\sum_{i=1}^{m} \sum_{j=1}^{n} X_{i j} Y_{i j}\]两矩阵内积实际上就是将矩阵的元素按一定的顺序排列后所生成的 $\mathbf{R}^{m n}$ 中相应向量的内积。
Frobenius 范数($\neq \ell_{2}$-范数)
\[\|X\|_{F}=\left(\operatorname{tr}\left(X^{T} X\right)\right)^{1 / 2}=\left(\sum_{i=1}^{m} \sum_{j=1}^{n} X_{i j}^{2}\right)^{1 / 2}\]Frobenius 范数实际上就是将矩阵的系数按一定顺序排列后所生成的相应向量的 Euclid 范数。
范数,距离以及单位球
满足以下条件的函数 $f$ 称为范数,
\[f: \mathbf{R}^{n} \rightarrow \mathbf{R}, \operatorname{dom} f=\mathbf{R}^{n}\]- $f$ 是非负的: 对所有的 $x \in \mathbf{R}^{n}$ 成立 $f(x) \geqslant 0$,
- $f$ 是正定的: 仅对 $x=0$ 成立 $f(x)=0$,
- $f$ 是齐次的: 对所有的 $x \in \mathbf{R}^{n}$ 和 $t \in \mathbf R$ 成立 $f(tx)=\lvert t \rvert f(x)$,
- $f$ 满足三角不等式: 对所有的 $x, y \in \mathbf{R}^{n}$ 成立 $f(x+y) \leqslant f(x)+f(y)$ 。
范数是对向量 $x$ 的长度的度量,用两个向量 $x$ 和 $y$ 的差异的长度度量它们之间的距离,即
\[\operatorname{dist}(x, y)=\|x-y\|\]范数小于等于1的所有向量的集合
\[\mathcal{B}=\left\{x \in \mathbf{R}^{n} \mid\|x\| \leqslant 1\right\}\]称为范数 $\Vert \cdot \Vert$ 的单位球。
$\ell_{p}$-范数
\[\|x\|_{p}=\left(\left|x_{1}\right|^{p}+\cdots+\left|x_{n}\right|^{p}\right)^{1 / p}\]取 $p=1$ 就得到 $\ell_{1}$-范数, $p=2$ 就得到 Euclid 范数(又名谱范数或者$\ell_{2}$-范数),又因为
\[\lim _{p \rightarrow \infty}\|x\|_{p}=\max \left\{\left|x_{1}\right|, \cdots,\left|x_{n}\right|\right\}\]因此 $\ell_{\infty}$-范数作为一种极限情况也属于这类范数。
二次范数
对 $P \in \mathbf{S}_{++}^{n}$, 我们定义 $P$-二次范数如下
\[\|x\|_{P}=\left(x^{T} P x\right)^{1 / 2}=\left\|P^{1 / 2} x\right\|_{2}\]二次范数的单位球是椭圆(反之,如果一个范数的单位球是椭圆,该范数就是二次范数)。
线性代数
值域和零空间
$A \in \mathbf{R}^{m \times n}$,$A$ 的值域, 用 $\mathcal{R}(A)$ 表示
\[\mathcal{R}(A)=\left\{A x \mid x \in \mathbf{R}^{n}\right\}\]值域 $\mathcal{R}(A)$ 是 $\mathbf{R}^{m}$ 的子空间,它的维数是 $A$ 的秩
$A$ 的零空间 (或核),用 $\mathcal{N}(A)$ 表示, 是被 $A$ 映射成零的所有向量 $x$ 的集合
\[\mathcal{N}(A)=\{x \mid A x=0\} .\]零空间是 $\mathbf{R}^{n}$ 的子空间
如果 $\mathcal{V}$ 是 $\mathbf{R}^{n}$ 的子空间, 它的正交补, 用 $\mathcal{V}^{\perp}$ 表示, 定义为
\[\mathcal{V}^{\perp}=\{x \mid z^{T} x=0 对所有 z \in \mathcal{V} 成立 \}\]线性代数的一个基本结果是, 对任意的 $A \in \mathbf{R}^{m \times n}$, 我们有
\[\mathcal{N}(A)=\mathcal{R}\left(A^{T}\right)^{\perp}\] \[\mathcal{N}(A) \stackrel{\perp}{\oplus} \mathcal{R}\left(A^{T}\right)=\mathbf{R}^{n}\]这里符号 $\oplus$ 指正交直和, 即两个正交子空间之和。 $\mathbf{R}^{n}$ 的分解(上式)被称为 $\boldsymbol{A}$ 导出的正交分解。
对称特征值分解
假设 $A \in \mathbf{S}^{n}$, 即 $A$ 是实对称 $n \times n$ 矩阵。那么 $A$ 可以因式分解为
\[A=Q \Lambda Q^{T}\]其中 $Q \in \mathbf{R}^{n \times n}$ 是正交矩阵, 即满足 $Q^{T} Q=I$, 而 $\Lambda=\operatorname{diag}\left(\lambda_{1}, \cdots, \lambda_{n}\right)$ 。 上述分解中的(实)数 $\lambda_{i}$ 是 $A$ 的特征值, 是特征多项式 $\operatorname{det}(s I-A)$ 的根。 $Q$ 的列向量构成 $A$ 的一组正交特征向量。上述因式分解被称为 $A$ 的谱分解或(对称)特征值分解。
\[\operatorname{det} A=\prod_{i=1}^{n} \lambda_{i}, \quad \operatorname{tr} A=\sum_{i=1}^{n} \lambda_{i},\]而谱范数和 Frobenius 范数同样可以表示成
\[\|A\|_{2}=\max _{i=1, \cdots, n}\left|\lambda_{i}\right|, \quad\|A\|_{F}=\left(\sum_{i=1}^{n} \lambda_{i}^{2}\right)^{1 / 2}\]对任意的 $x$,我们有
\[\lambda_{\min }(A) x^{T} x \leqslant x^{T} A x \leqslant \lambda_{\max }(A) x^{T} x\]矩阵 $A \in \mathbf{S}^{n}$ 是正定矩阵的条件是,对所有的 $x \neq 0$ 成立 $x^{T} A x>0$。用 $A \succ 0$ 表示正定矩阵。从以上不等式可以看出, $A \succ 0$ 的充要条件是它的所有特征根都是正数,即 $\lambda_{\min }(A)>0$。用 $\mathbf S_{++}^{n}$ 表示 $\mathbf{S}^{n}$ 中所有正定矩阵的集合;$x^{T} A x \geqslant 0$ 对应的 $A$ 是半正定矩阵或是非负定矩阵。我们用 $\mathbf{S}_{+}^{n}$ 表示 $\mathbf{S}^{n}$ 中所有非负定矩阵的集合。
对 $A, B \in \mathbf{S}^{n}$, 我们用 $A \prec B$ 表示 $B-A \succ 0$, 其他情况类似。这些不等式称为矩阵不等式
对称平方根
令 $A \in \mathbf S_{+}^{n}$ 的特征值分解为 $A=Q \operatorname{diag}\left(\lambda_{1}, \cdots, \lambda_{n}\right) Q^{T}$ 。我们定义 $A$ 的(对称)平方根为
\[A^{1 / 2}=Q \operatorname{diag}\left(\lambda_{1}^{1 / 2}, \cdots, \lambda_{n}^{1 / 2}\right) Q^{T}\]平方根 $A^{1 / 2}$ 是矩阵方程 $X^{2}=A$ 的唯一的对称半正定的解。
广义特征值分解
两个对称矩阵 $(A, B) \in \mathbf{S}^{n} \times \mathbf{S}^{n}$ 的广义特征值定义为多项式 $\operatorname{det}(s B-A)$ 的根。
对于 $B \in \mathbf{S}_{++}^{n}$,广义特征值和 $B^{-1 / 2} A B^{-1 / 2}$ (这是实矩阵)的特征值相同。
广义特征值分解:当 $B \in \mathbf{S}_{++}^{n}$ 时,以上两个矩阵可以因式分解为
\[A=V \Lambda V^{T}, \quad B=V V^{T} \tag{A.11}\]其中 $V \in \mathbf{R}^{n \times n}$ 是非奇异矩阵(可逆), $\Lambda=\operatorname{diag}\left(\lambda_{1}, \cdots, \lambda_{n}\right)$, 而 $\lambda_{i}$ 代表矩阵对 $(A, B)$ 的广义特征值。
广义特征值分解和矩阵 $B^{-1 / 2} A B^{-1 / 2}$ 的标准特征值分解关系:如果 $Q \Lambda Q^{T}$ 是 $B^{-1 / 2} A B^{-1 / 2}$ 的特征值分解, 那么式 $(A.11)$ 对 $V=B^{1 / 2} Q$ 成立。
奇异值分解
当 $A \notin \mathbf{S}^{n}$ 时,假设 $A \in \mathbf{R}^{m \times n}, \operatorname{rank} A=r$。那么 $A$ 可以因式分解为
\[A=U \Sigma V^{T} \tag{A.12},\]其中 $U \in \mathbf{R}^{m \times r}$ 满足 $U^{T} U=I, V \in \mathbf{R}^{n \times r}$ 满足 $V^{T} V=I$, 而 $\Sigma=\operatorname{diag}\left(\sigma_{1}, \cdots, \sigma_{r}\right)$ 满足
\[\sigma_{1} \geqslant \sigma_{2} \geqslant \cdots \geqslant \sigma_{r}>0\]因式分解 $(A.12)$ 称为 $A$ 的奇异值分解 $(\mathrm{SVD})$。$U$ 的列向量称为 $A$ 的左奇异向量, $V$ 的列向量称为右奇异向量, 而 $\sigma_{i}$ 则称为奇异值。奇异值分解可以写成
\[A=\sum_{i=1}^{r} \sigma_{i} u_{i} v_{i}^{T}\]其中 $u_{i} \in \mathbf{R}^{m}$ 是左奇异向量, $v_{i} \in \mathbf{R}^{n}$ 是右奇异向量。
注意到:奇异值分解对 $A$ 没有对称的要求,无论是左(右)奇异向量,还是特征向量,都是正交矩阵,奇异值均为非负数。矩阵 $A$ 的奇异值分解和 (对称非负定)矩阵 $A^{T} A$ 的特征值分解的关系:
\[A^{T} A=V \Sigma^{2} V^{T}=\left[\begin{array}{ll} V & \tilde{V} \end{array}\right]\left[\begin{array}{cc} \Sigma^{2} & 0 \\ 0 & 0 \end{array}\right]\left[\begin{array}{ll} V & \tilde{V} \end{array}\right]^{T}\]由于 $V$ 只有 $n \times r$ 而对 $A^{T} A$ 特征值分解得到的特征向量应该是 $n \times n$,而且 $V$ 和 特征分解得到的特征向量都是正交矩阵,所以,需要有 $\tilde{V}$,其是使 $[V \tilde{V}]$ 成为正交矩阵的任何矩阵。上式右边是 $A^{T} A$ 的特征值分解, 因此 可以声称它的非零特征值就是 $A$ 的奇异值的平方, 而 $A^{T} A$ 的非零特征值对应的特征向量就是 $A$ 的右特征向量。对 $A A^{T}$ 进行类似的分析可以表明它的非零特征值就是 $A$ 的奇异值的平方, 而相应的特征向量就是 $A$ 的左特征向量。
对称矩阵的奇异值就是其非零特征值以下降顺序排列的绝对值。对称半正定矩阵的奇异值和它的非零特征值相同(特征向量也相同)。
非奇异矩阵 $A \in \mathbf{R}^{n \times n}$ 的条件数, 用 $\operatorname{cond}(A)$ 或 $\kappa(A)$ 表示, 定义为
\[\operatorname{cond}(A)=\|A\|_{2}\left\|A^{-1}\right\|_{2}=\sigma_{\max }(A) / \sigma_{\min }(A)\]伪逆
令 $A=U \Sigma V^{T}$ 为 $A \in \mathbf{R}^{m \times n}$ 的奇异值分解, $\operatorname{rank} A=r$ 。我们定义 $A$ 的伪逆或 Moore-Penrose 逆如下
\[A^{\dagger}=V \Sigma^{-1} U^{T} \in \mathbf{R}^{n \times m} .\]若 $r=n$,
\[A^{\dagger}=(A^T A)^{-1} A^{T} .\]若 $r=m$,
\[A^{\dagger}=A^{T} (A A^T)^{-1} .\]Schur 补
考虑进行以下划分的矩阵 $X \in \mathbf{S}^{n}$,
\[X=\left[\begin{array}{cc} A & B \\ B^{T} & C \end{array}\right]\]其中 $A \in \mathbf{S}^{k}$ 。如果 $\operatorname{det} A \neq 0$, 矩阵
\[S=C-B^{T} A^{-1} B\]被称为 $A$ 在 $X$ 中的 Schur 补。在多种情况下会遇到 Schur 补, 它出现于很多重要的公式和定理中。例如, 我们有
\[\operatorname{det} X=\operatorname{det} A \operatorname{det} S .\]LU, Cholesky 和 $LDL^{T}$ 因式分解
见凸优化一书C.3
正交和投影
二维投影
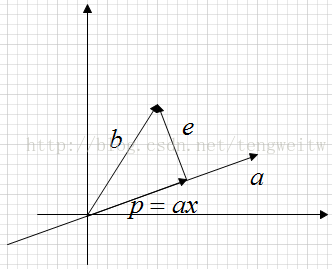
上图表示的是,向量b在向量a上的投影。显然有如下表达式:
$e=b-p=b-x a$
$a^{T} e=0 \rightarrow a^{T}(b-x a)=0 \rightarrow x a^{T} a=a^{T} b \rightarrow x=\frac{a^{T} b}{a^{T} a}$
$p=a x=a \frac{a^{T} b}{a^{T} a}$
$P b=p \rightarrow P=\frac{a a^{T}}{a^{T} a}$
其中, P为投影矩阵,由P的表达式可以看出,它具有如下性质:
$P^{T}=P$
$P^{2}=P$
三维投影
如果 $A$ 列向量线性无关(即列满秩),$A^{T} A$ 可逆$\Longleftrightarrow A^T AX=0$可以推出 $X=0$
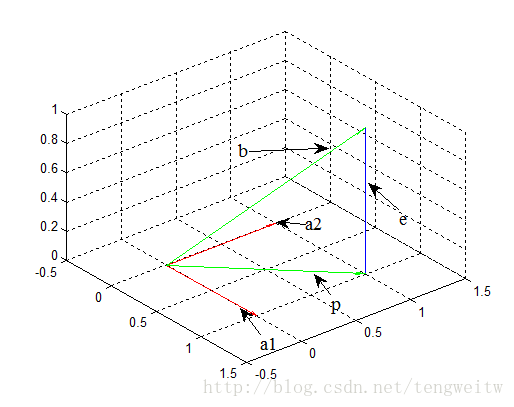 三维投影,就是将一个向量投影到一个平面上。同上面一样,假设是将 $b$ 向量投影到平面上的 $p$ 向量, 则有表达式:
三维投影,就是将一个向量投影到一个平面上。同上面一样,假设是将 $b$ 向量投影到平面上的 $p$ 向量, 则有表达式:
$e=b-p$
e是垂直与平面的向量。由于 $p$ 向量在平面上,则 $p$ 向量可以由该平面的2个线性无关向量(正如,在xy平面的任何向量都可以由 $x$ 轴, $y$ 轴表示)表示:
$p=x_{1} a_{1}+x_{2} a_{2}=A x$
$A=\left[\begin{array}{ll}a_{1} & a_{2}\end{array}\right]$
$x=\left[\begin{array}{ll}x_{1} & x_{2}\end{array}\right]^T$
由于 $e$ 垂直平面,则 $e$ 向量垂直于平面中的任意向量, 则有:
$e=b-p=b-A x$
$a_{1}^{T}(b-A x)=0$
$a_{2}^{T}(b-A x)=0$
将上式化简求得x:
$A^{T} A x=A^{T} b$
$x=\left(A^{T} A\right)^{-1} A^{T} b$
又因为 $\mathrm{p}=\mathrm{Ax}, \mathrm{Pb}=\mathrm{p}$, 则得到投影矩阵为:
$P=A\left(A^{T} A\right)^{-1} A^{T}$
由P的表达式可以看出,它具有如下性质:
$P^{T}=P$
$P^{2}=P$
上面的投影矩阵是通式,当考虑二维投影时, $A$ 即为直线上的任意一个向量 $a$,投影矩阵为:
标准正交基
QR分解
函数
连续
如果对任意的 $\epsilon>0$ 都存在 $\delta$ 满足
\[y \in \operatorname{dom} f, \quad\|y-x\|_{2} \leqslant \delta \Longrightarrow\|f(y)-f(x)\|_{2} \leqslant \epsilon\]则称函数 $f: \mathbf{R}^{n} \rightarrow \mathbf{R}^{m}$ 在 $x \in \operatorname{dom} f$ 处连续。
闭函数
对于函数 $f: \mathbf{R}^{n} \rightarrow \mathbf{R}$, 如果每个 $\alpha \in \mathbf{R}$ 对应的下水平集
\[\{x \in \operatorname{dom} f \mid f(x) \leqslant \alpha\}\]是闭集, 就说这个函数是闭函数。(类比拟凸函数:凸集)
性质: 如果 $f: \mathbf{R}^{n} \rightarrow \mathbf{R}$ 连续, 并且 $\operatorname{dom} f$ 是闭的, 那么 $f$ 是闭函数。如果 $f: \mathbf{R}^{n} \rightarrow \mathbf{R}$ 连续, $\operatorname{dom} f$ 是开集, 那么 $f$ 是闭函数的充要条件是 $f$ 将沿着任何收敛于 $\operatorname{dom} f$ 的边界点的序列趋于 $\infty$。换言之,如果 $\lim_{i \rightarrow \infty} x_{i}=x \in \mathbf{b d} \operatorname{dom} f$, 其中 $x_{i} \in \operatorname{dom} f$,我们有 $\lim_{i \rightarrow \infty} f\left(x_{i}\right)=\infty$ 。
导数
假定 $f: \mathbf{R}^{n} \rightarrow \mathbf{R}^{m}, x \in$ int $\operatorname{dom} f$ 。函数 $f$ 在 $x$ 处可微的定义是, 存在矩阵 $D f(x) \in \mathbf{R}^{m \times n}$ 满足
\[\lim _{z \in \operatorname{dom} f, z \neq x, z \rightarrow x} \frac{\|f(z)-f(x)-D f(x)(z-x)\|_{2}}{\|z-x\|_{2}}=0 \tag{A.4}\]在这种情况下我们将 $D f(x)$ 称为 $f$ 在 $x$ 处的导数(或Jacobian 矩阵)。(至多只有一个矩阵能够满足式 $(A.4)$。) 如果 $\operatorname{dom} f$ 是开集, 并且函数 $f$ 在其定义域内处处可微, 我们称其为可微函数。
偏导数:
\[D f(x)_{i j}=\frac{\partial f_{i}(x)}{\partial x_{j}}, \quad i=1, \cdots, m, \quad j=1, \cdots, n\]梯度:
对于实函数 $f$ (即 $f: \mathbf{R}^{n} \rightarrow \mathbf{R}$ ), 导数 $D f(x)$ 是 $1 \times n$ 的矩阵, 即行向量。它的转置称为函数的梯:
\[\nabla f(x)=D f(x)^{T}\]这是一个 (列) 向量, 即属于 $\mathbf{R}^{n}$ 。它的分量是 $f$ 的偏导数:
\[\nabla f(x)_{i}=\frac{\partial f(x)}{\partial x_{i}}, \quad i=1, \cdots, n\]链式规则
假设 $f: \mathbf{R}^{n} \rightarrow \mathbf{R}^{m}$ 在 $x \in int \operatorname{dom} f$ 处可微, $g: \mathbf{R}^{m} \rightarrow \mathbf{R}^{p}$ 在 $f(x) \in int \operatorname{dom} g$ 处可微。定义复合函数 $h: \mathbf{R}^{n} \rightarrow \mathbf{R}^{p}$ 为 $h(z)=g(f(z))$ 。则 $h$ 在 $x$ 处可微, 导数为
\[D h(x)=D g(f(x)) D f(x)\]作为一个例子,假设
\[f: \mathbf{R}^{n} \rightarrow \mathbf{R}, g: \mathbf{R} \rightarrow \mathbf{R}, h(x)=g(f(x))\]对 $D h(x)=D g(f(x)) D f(x)$ 转置得到
\[\nabla h(x)=g^{\prime}(f(x)) \nabla f(x)\]二阶导数
本节我们回顾实函数 $f: \mathbf{R}^{n} \rightarrow \mathbf{R}$ 的二阶导数。如果函数 $f$ 在 $x$ 处二次可微, 那 么 $f$ 在 $x \in$ int $\operatorname{dom} f$ 处的二阶导数或 Hessian 矩阵, 用 $\nabla^{2} f(x)$ 表示, 就是
\[\nabla^{2} f(x)_{i j}=\frac{\partial^{2} f(x)}{\partial x_{i} \partial x_{j}}, \quad i=1, \cdots, n, \quad j=1, \cdots, n\]其中偏导数都在 $x$ 处取值。函数 $f$ 在 (或) 接近 $x$ 处以 $z$ 为变量的二次逼近为
\[\widehat{f}(z)=f(x)+\nabla f(x)^{T}(z-x)+(1 / 2)(z-x)^{T} \nabla^{2} f(x)(z-x) .\]该二次逼近满足
\[\lim _{\operatorname{dom} f, z \neq x, z \rightarrow x} \frac{|f(z)-\widehat{f}(z)|}{\|z-x\|_{2}^{2}}=0\]二阶导数可以解释为一阶导数的导数。
二阶导数的链式规则
